Paper: Cassandra
Cassandra / Distributed Wide Column NoSQL Database
Goal
Design a distributed and scalable system that can store a huge amount of semi-structured data, which is indexed by a row key where each row can have an unbounded number of columns.
Background
- Open source Apache Project developed at FB in 2007 for Inbox Search feature.
- Designed to provide Scalability, Availability, Reliability to store large amounts of data.
- Combines distributed nature of Amazon’s Dynamo(K-V store) and DataModel for Google’s BigTable which is a Column based store.
- Decentralized architecture with no Single Point of Failure(SPOF), Performance can scale linearly with addition of nodes.
What is Cassandra?
- Cassandra is typically classified as an AP (i.e., Available and Partition Tolerant) system which means that availability and partition tolerance are generally considered more important than the consistency. Eventually Consistent
- Similar to Dynamo, Cassandra can be tuned with replication-factor and consistency levels to meet strong consistency requirements, but this comes with a performance cost.
- Uses peer-to-peer architecture where each node communicates to all other nodes.
Cassandra Use Cases
- Any application where eventual consistency is not a concern can utilize Cassandra.
- Cassandra is optimized for high throughput writes.
- Can be used for collecting big data for performing real-time analysis.
- Storing key-value data with high availability(Reddit/Dig) because of linear scaling w/o downtime.
- Time Series Data Model
- Write Heavy Applications
- NoSQL
High Level Architecture
Agenda
- Cassandra Common Terms
- High Level Architecture
Cassandra Common Terms
Column: A Key-Value pair. Most basic unit of data structure in Cassandra.
Row: Container for columns referenced by the primary key.
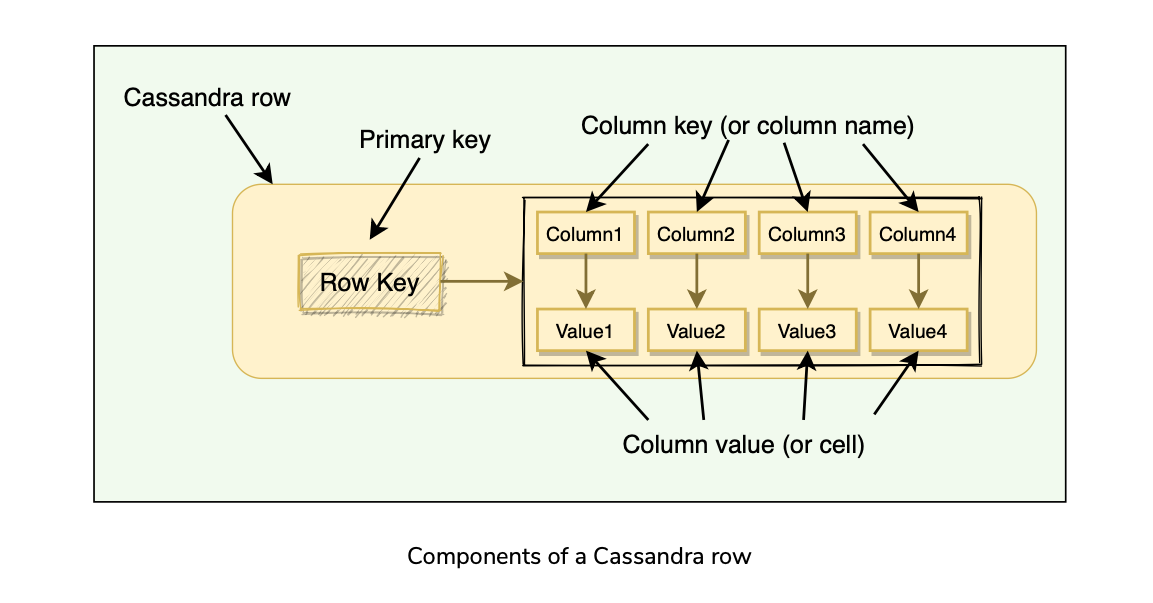
Table: Container of rows.
KeySpace: Container for tables that span over one or more cassandra nodes.
Cluster : Container of KeySpaces.
Node: Computer system running cassandra instance. Physical Host, or VM, or even Docker container.
Data Partitioning
- Cassandra uses Consistent Hashing similar to Dynamo.
Cassandra Keys
- Mechanisms used by Cassandra to uniquely identify the rows.
- Primary Key uniquely identifies each row of a table.
- Primary Key = Partition Key + Clustering Key
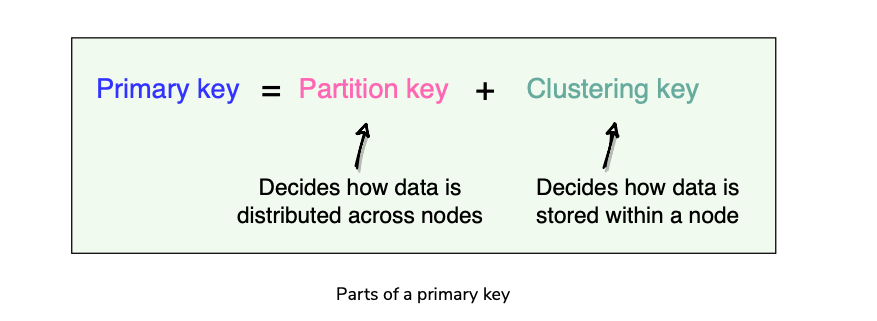
Clustering Keys
- Clustering keys define how the data is stored within a node. Can have multiple clustering keys.
Partitioner
Component which is responsible for determining how the data is distributed on the consistent hashing ring.
When cassandra inserts some data, partitioning applies a hashing algorithm to the partition Key to determine which range(and the corresponding node) the data lies.
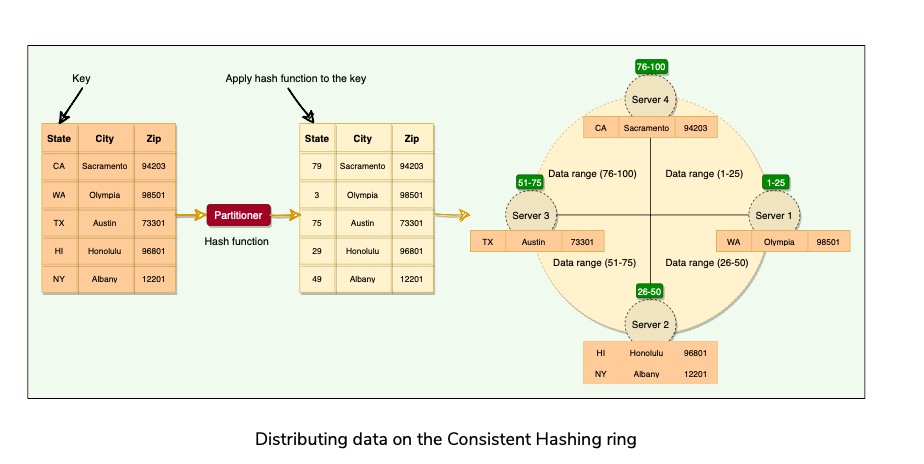
Cassandra uses Murmer3 hashing function(Default).
In cassandra’s default configuration, a token is a 64-bit integer. Gives possible token ranges from [-2^63 , 2^63 + 1]. How does it differ from Dynamo?
All nodes learn about token assignment of other nodes through Gossip.
Replication
Agenda
- Replication Factor
- Replication Strategy.
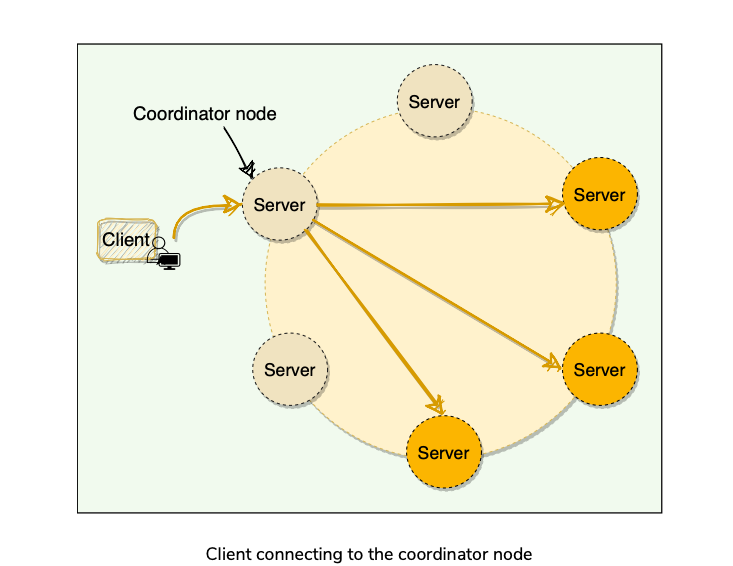
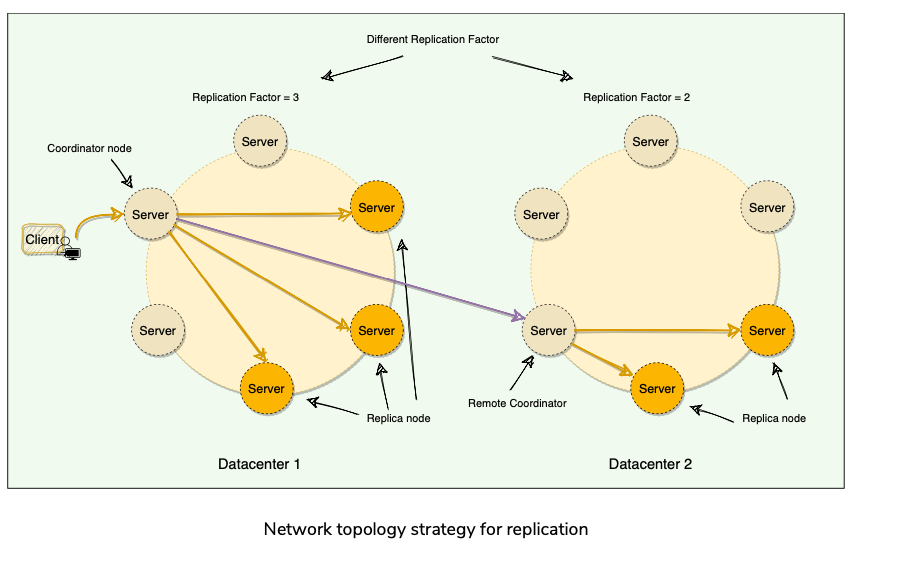
- Each node in Cassandra serves as a replica for a different range of data. Replication factor decides how many replicas the system would have, which is the number of nodes that will receive the copy of the same data.
- The node that owns the range in which hash of the partition key falls is the first replica. All additional replicas are placed on the consecutive nodes in a clockwise manner.
- Simple Replication Strategy
- Network Topology Strategy
Cassandra Consistency Levels
Agenda
- Cassandra Consistency Levels
- Write Consistency Levels
- Read consistency level
- Snitch
Cassandra Consistency Levels
- Minimum number of Cassandra nodes that must fulfill a read or write operation before the operation can be considered successful.
- Has Tunable Consistency levels for reads and writes.
- Tradeoff b/w Consistency and performance.
Write Consistency Levels
- One or Two or Three : Success acknowledgement from specified number of nodes**.**
- Quorum: Data must be written to at least the Majority Quorum of nodes.
- All: Data is written to all nodes.
- Local Quorum: Data is written to the Quorum of nodes in the same data center as the coordinator. Don’t wait for responses from other Data Centers.
- Each Quorum: Data written to the Quorum of nodes in each data center.
- Any: Data written to at least one node**.**
- Performing Write Operation? Hinted Handoff?
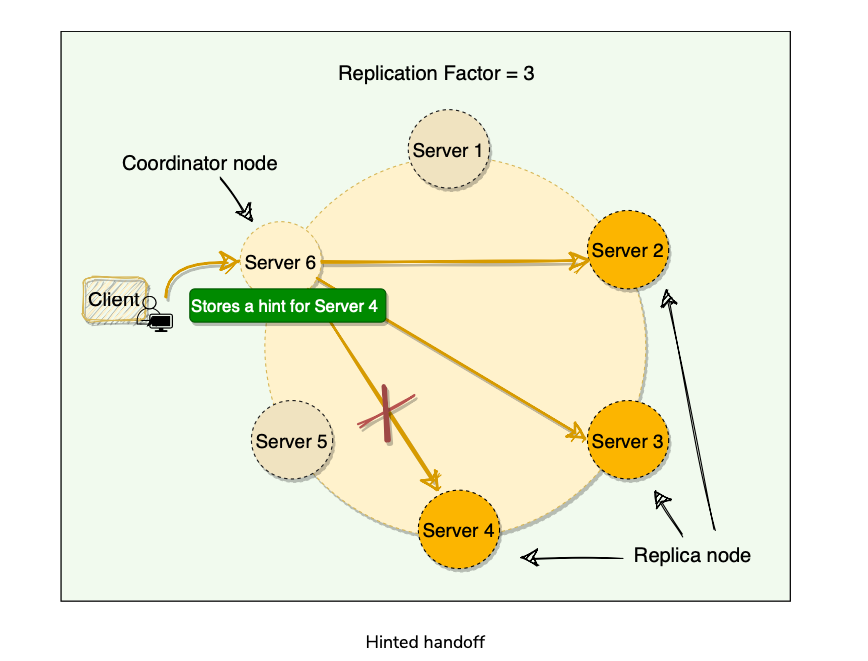
- When the node where the data was supposed to be written for Quorum was down comes online again, how should we write data to it? Cassandra accomplishes this through a Hinted handoff.
- [FAILURE MODE] When a node is down or does not respond to a write request, the coordinator node writes a hint in a text file on the local disk. This hint contains the data itself along with information about which node the data belongs to. When the coordinator node discovers(using Gossip Protocol) that a node for which it holds hints has recovered, it forwards the write requests for each hint to the target. Furthermore, each node every ten minutes checks to see if the failing node, for which it is holding any hints, has recovered.
- [FAILURE MODE] If a node is offline for some time, the hints can build up considerably on other nodes. Now, when the failed node comes back online, other nodes tend to flood that node with write requests. This can cause issues on the node, as it is already trying to come back after a failure.
- Cassandra by default stores hints for 3 hours. After 3 hours, older hints are removed , if the failed node comes back up(hinted handoff won’t happen), and the node would contain stale data. Stale data can be fixed by Read-Repair(Read Path)
- When the cluster cannot meet the client’s consistency level, cassandra fails the write request, and doesn’t store a hint.
Read Consistency Levels
- Specifies how many replica nodes must respond to a read request before returning the data.
- Same levels as Write operations except(Each Quorum) because Expensive.
- R + W > Replication Factor can give Strong consistency levels in Cassandra?[Research]
- Cassandra uses Snitch, an application that determines the proximity of nodes within the ring and also tells which nodes are faster and cassandra uses this to route read/write requests.
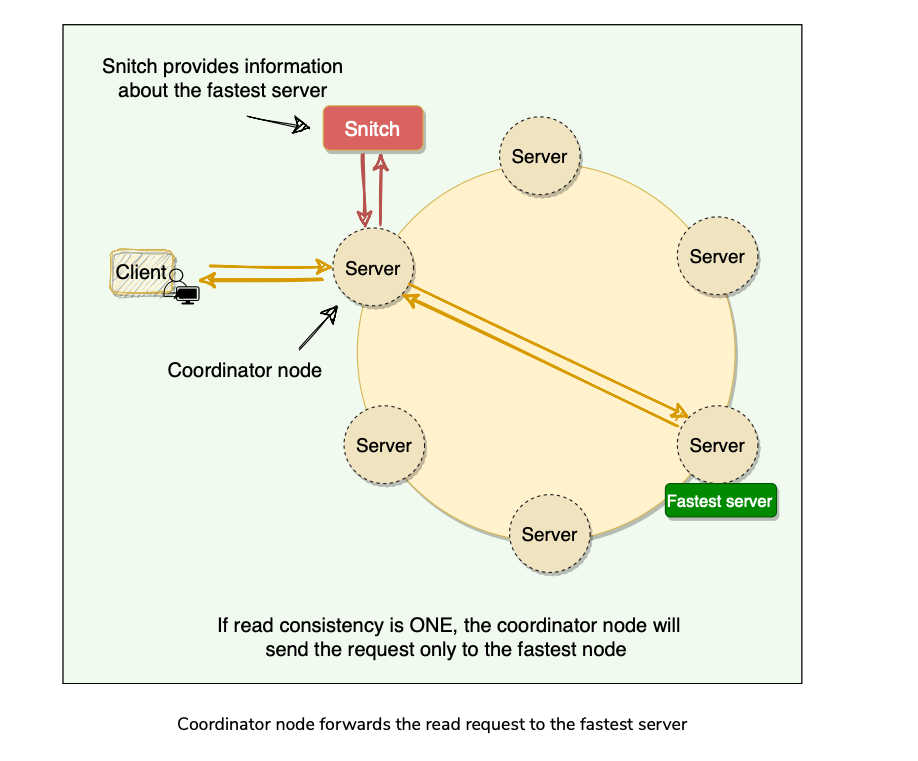
How does Cassandra perform a Read Operation?
Coordinator sends the read request to the fastest node(using Snitch).
E.g. Quorum R = 2, sends the request to the fastest node, and digest of the data from the second fastest node.
If the digest does not match, it means some replicas do not have the latest version of the data. In this case, the coordinator reads the data from all the replicas to determine the latest data.
The coordinator then returns the latest data to the client and initiates a read repair request.
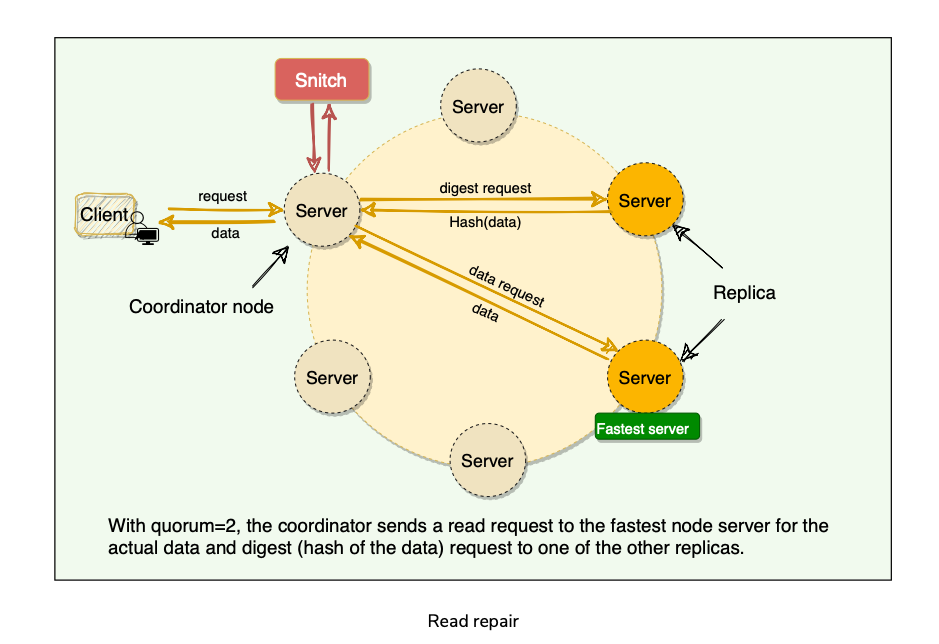
The latest write-timestamp is used as a marker for the correct version of data[Research?] in Cassandra? Conflict resolution? Last write wins or Vector Clocks? Data Loss?
The read repair operation is performed only in a portion of the total reads to avoid performance degradation.
By default, Cassandra tries to read-repair 10% of all requests with DC local read repair.
Snitch
- Snitch keeps track of network topology of Cassandra nodes. It determines which data center and racks nodes belong to and uses this info to route requests efficiently.
- Functions of Snitch in Cassandra?
Gossiper
- How does Cassandra use the Gossip protocol?
- Node failure detection?
How does Cassandra use the Gossip Protocol?
Allows each node to keep track of state information about other nodes in the cluster.
Gossip protocol is a peer-to-peer communication mechanism in which nodes periodically exchange state information about themselves and other nodes they know about.
Each node initiates a gossip round every second to exchange state information about themselves (and other nodes) with one to three other random nodes.
Each Gossip message has a version associated with it, so that during gossip exchange, older information is overwritten with the most current state for a particular node.
Generation Number: Each node tracks a generation number which increments every time a node restarts.
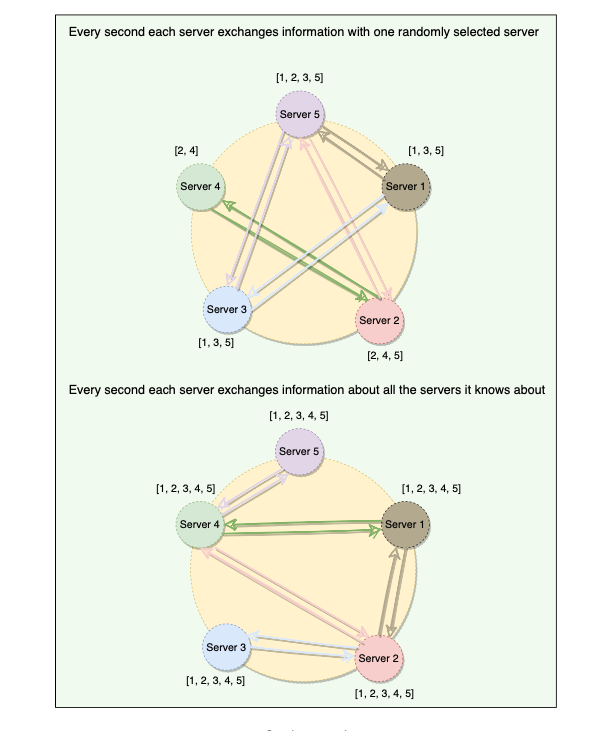
Seed Nodes?
Node Failure Detection?
- Accurately detecting failures is a hard problem to solve. We cannot say with 100% accuracy if a node is actually down or is just very slow to respond due to heavy load, network congestion, GC/process pauses etc.
- Heart Beating(Boolean Failure detector, Yes or No) uses a fixed timeout, and if there is no heartbeat from a server, the system, after the timeout, assumes that the server has crashed. Here the value of the timeout is critical.
- Cassandra uses an Adaptive failure detection mechanism, Phi Accrual Failure Detector
- A generic Accrual Failure Detector, instead of telling if the server is alive or not, outputs the suspicion level about a server; a higher suspicion level means there are higher chances that the server is down.
- Phi Accrual Failure Detector, if a node does not respond, its suspicion level is increased and could be declared dead later.
Anatomy of Cassandra’s write operation
Agenda
- CommitLog
- MemTable
- SSTable
- Cassandra stores data both in-memory and on-disk to provide both high performance and durability. Every write includes a timestamp. The Write-Path involves a lot of components.
- Cassandra’s Write path Summary:
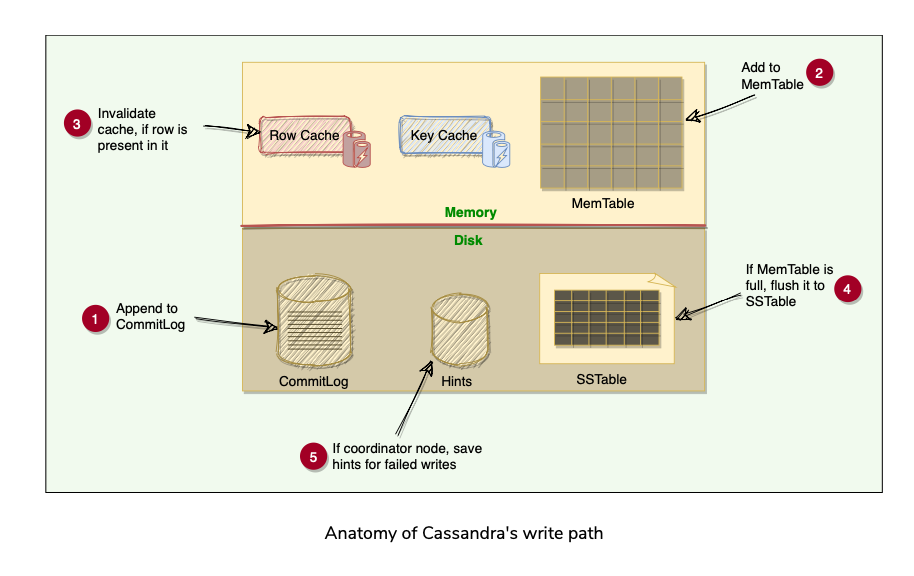
Commit Log
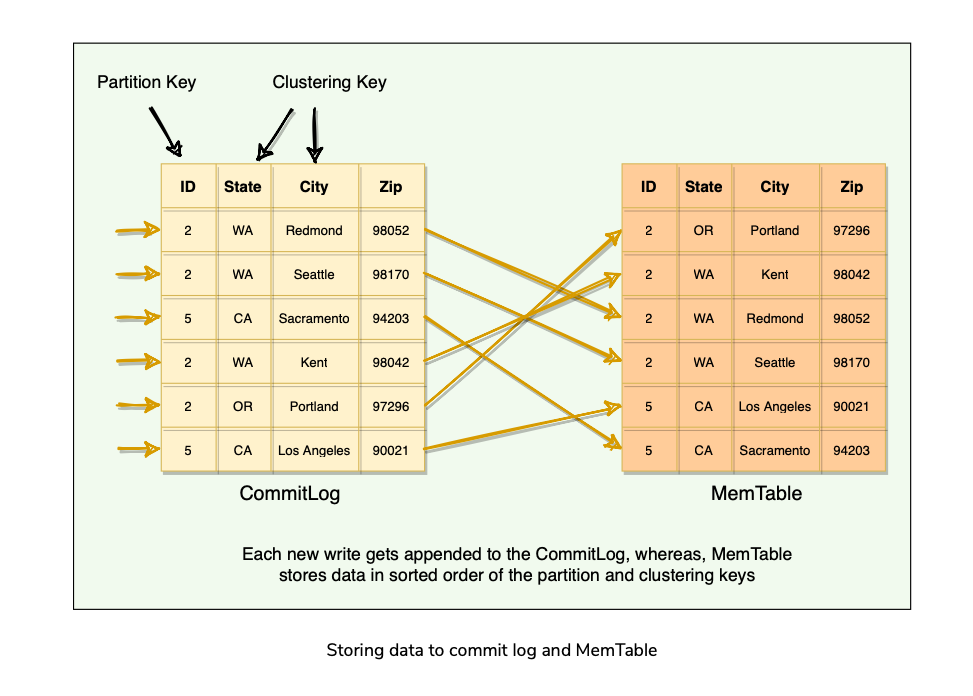
- When a node receives a write request, it immediately writes the data to a commit log.
- The commit log is a write-ahead log and is stored on disk.
- Used as a Crash-Recovery mechanism for Cassandra’s Durability goals.
- A write on the node isn’t considered successful until it’s written to the commit log.
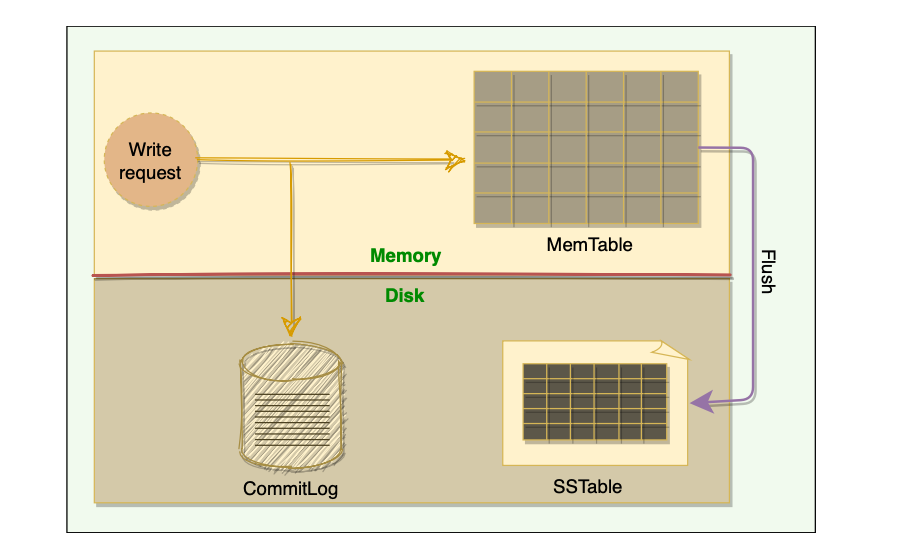
MemTable
- After a Write is persisted to CommitLog, it is then written to the memory-resident data structure which is MemTable.
- Each Cassandra node has an In-Memory MemTable for each Table. It resembles that data in that Table it represents.
- Accrues writes and provides reads for data not yet flushed to disk.
- Commit Log stores all the writes in sequential Order(append only log) whereas MemTable stores data in sorted order of PartitionKey, and Clustering Columns.
- After data is written to Commit-Log and MemTable, node sends success acknowledgement to the Coordinator.
SSTable(Sorted String Table)
- When the number of objects stored in the MemTable reaches a Threshold, the contents of the MemTable are flushed to disk in a file called SSTable.
- New MemTable is created to serve in-memory requests for subsequent data.
- Flushing of MemTables is a Non-Blocking operation.
- Multiple MemTables may exist for a single Table, one current, and others waiting to be flushed.
- SSTable contains data for a specific Table.
- When the MemTable is flushed to SStables, corresponding entries in the Commit Log are removed.
- The Term SSTable first appeared in Google’s Bigtable which is also a storage system. Cassandra borrowed this term even though it does not store data as strings on the disk.
- Once a MemTable is flushed to disk as an SSTable, it is immutable and cannot be changed by the application.
- If we are not allowed to update SSTables, how do we delete or update a column?
- The current data state of a Cassandra table consists of its MemTables in memory and SSTables on the disk.
- On reads, Cassandra will first read MemTables, and then subsequently SSTables(if MemTables Does Not contain the key) to find data values, as the MemTable may still contain values that have not yet been flushed to the disk.
- MemTable works as a WriteBack cache that Cassandra looks up by Key.
- Generation Number: an Index number that is incremented every time a new SSTable is created for a Table. Uniquely identifies an SSTable.
Anatomy of Cassandra’s read operation
Agenda
- Caching
- Reading from MemTable
- Reading from SSTable
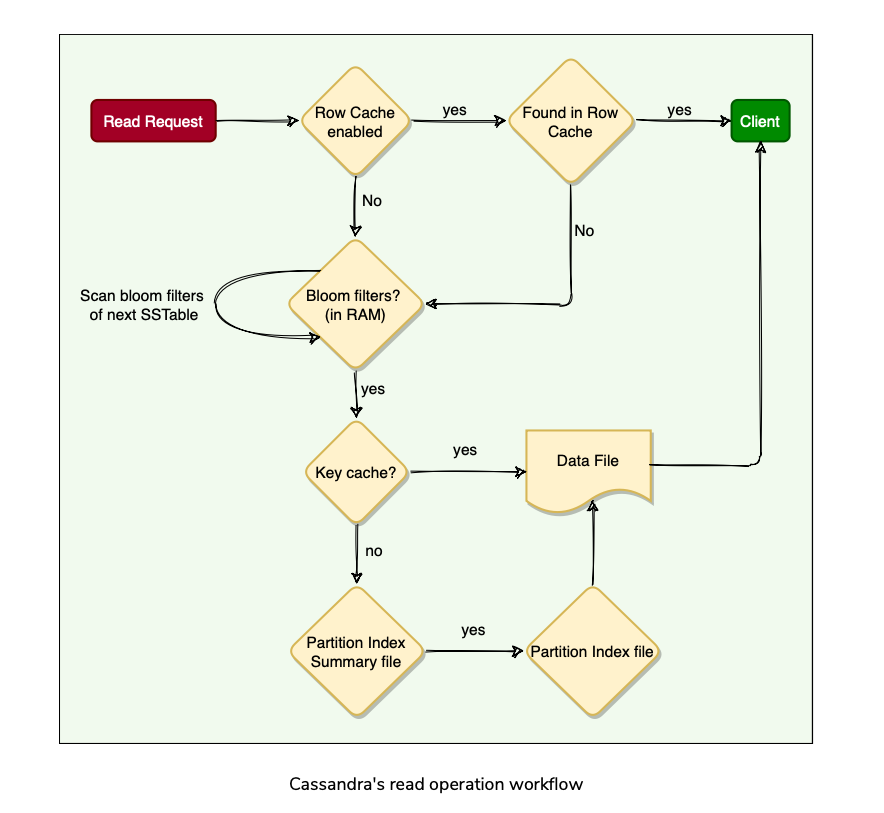
Caching
- To boost read performance, Cassandra provides 3 optional forms of caching:
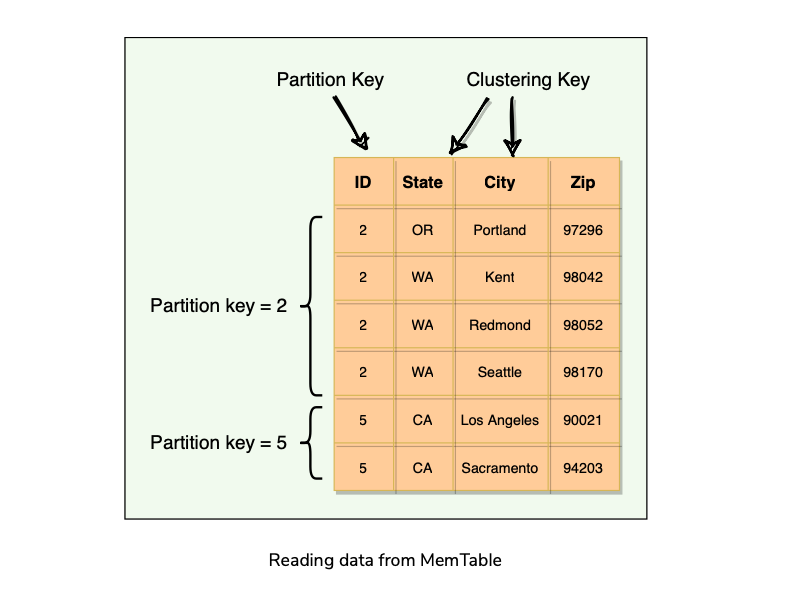
Reading from MemTable
- Data is sorted by the partition key and the clustering columns.
- When a read request comes in, the node performs a binary search on the partition key to find the required partition and then returns the row.
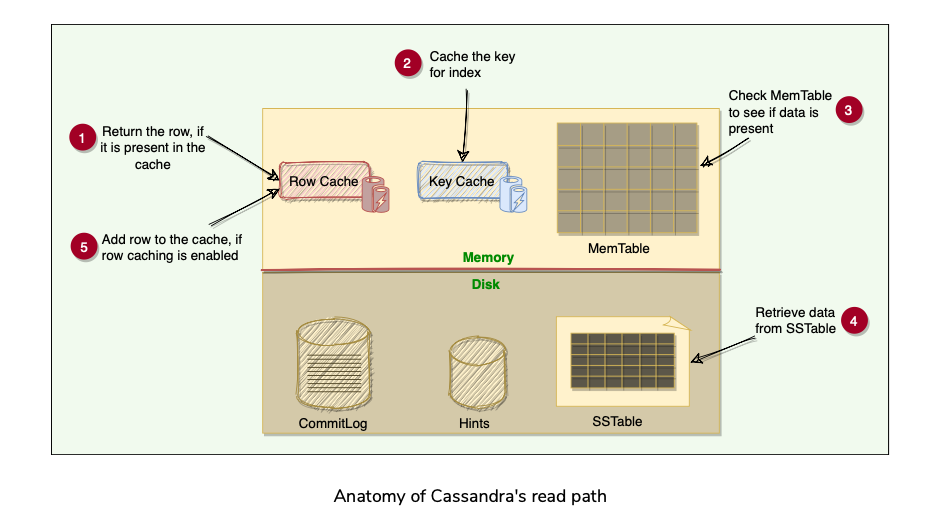
Reading from SSTables
Bloom Filters
- Each SStable has a Bloom filter associated with it, which tells(probabilistic) if a particular key is present in it or not for boosting read performance.
- Bloom filters are very fast, non-deterministic algorithms for testing whether an element is a member of a set.
- Bloom filters work by mapping the values in a data set into a bit array and condensing a larger data set into a digest string using a hash function.
- The filters are stored in memory and are used to improve performance by reducing the need for disk access on key lookups since disk access is much slower.
- Because false negatives are not possible:
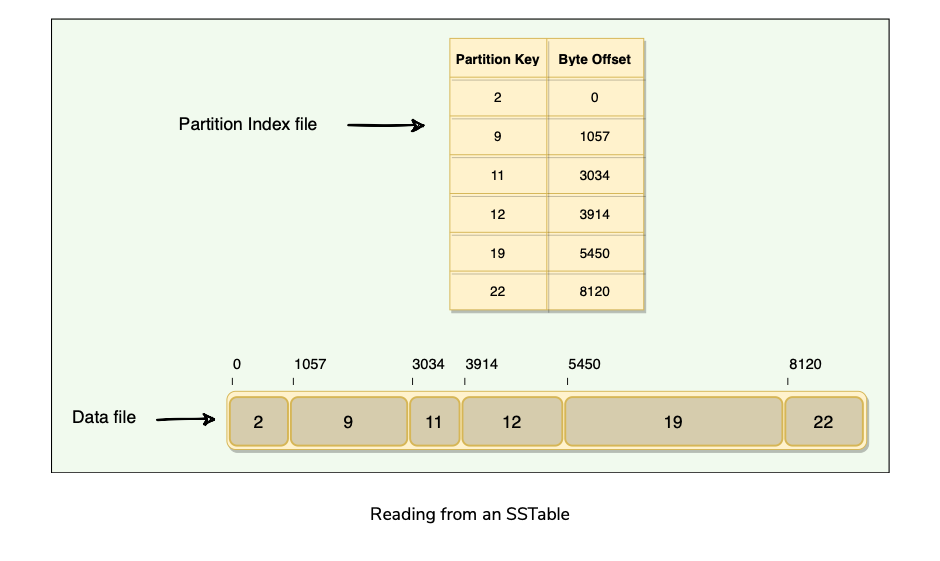
How are SSTables Stored on Disk?
Each SSTable Consists of Two Files:
Partition Index Summary File
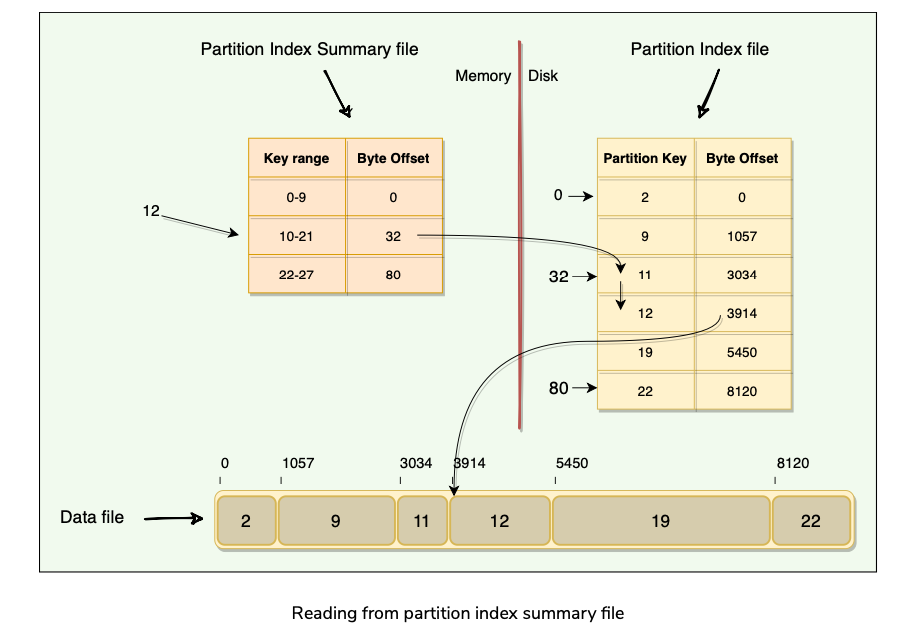
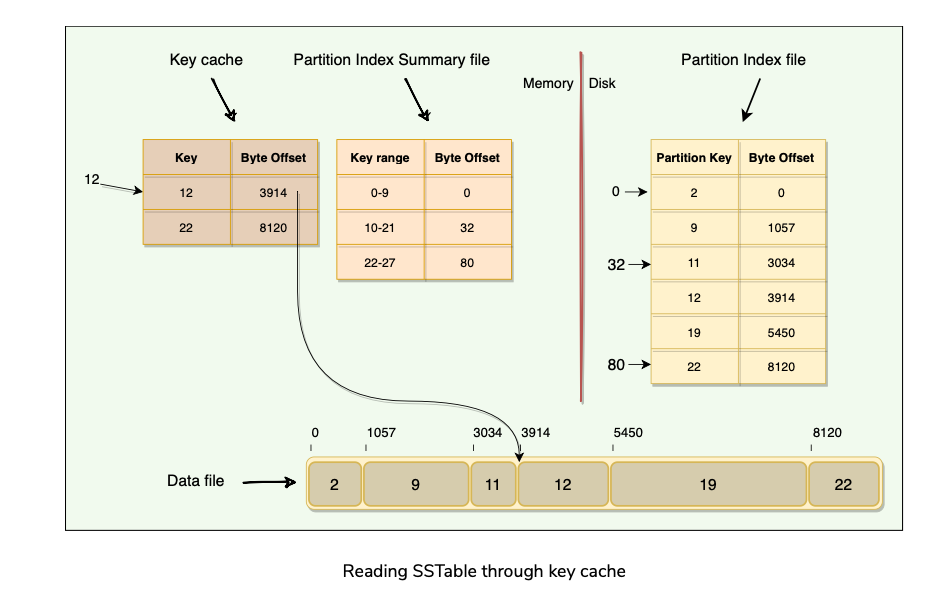
If we want to read data for key=12, here are the steps we need to follow (also shown in the figure below):
Reading SSTable through Key Cache
As the Key Cache stores a map of recently read partition keys to their SSTable offsets, it is the fastest way to find the required row in the SSTable.
Summary of Read Operation:
Compaction
Agenda
- How does compaction work in Cassandra?
- Compaction Strategies?
- Sequential Writes?
How does compaction work in Cassandra?
- SSTables are immutable(Append Only Log), which helps Cassandra achieve such high write speeds.
- Flushing of MemTable to SStable is a continuous process. This means we can have a large number of SStables lying on the disk. While reading, it is tedious to scan all these SStables. So, to improve the read performance, we need compaction.
- Compaction refers to the operation of merging multiple related SSTables into a single new one.
- During compaction, the data in SSTables is merged: the keys are merged, columns are combined, obsolete values are discarded, and a new index is created.
- On compaction, the merged data is sorted, a new index is created over the sorted data, and this freshly merged, sorted, and indexed data is written to a single new SSTable.
- Compaction will reduce the number of SSTables to consult and therefore improve read performance.
- Compaction will also reclaim space taken by obsolete(Tombstoned or overwritten) data in SSTables.
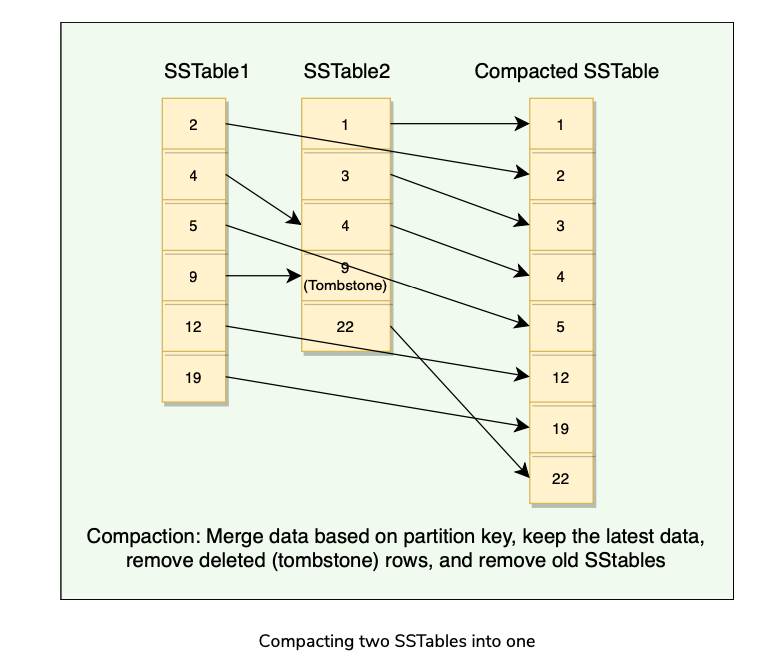
Compaction Strategies
- Size Tiered(Default, Write Optimized)
- Levelled(Read Optimized)
- Time Window(Time Series Optimized)
Sequential Writes
- Sequential writes are the primary reason that writes perform so well in Cassandra.
- No reads or seeks of any kind are required for writing a value to Cassandra because writes are append-only operations.
- Write speed of the disk becomes a performance bottleneck.
- Compaction is intended to amortize the reorganization of data, but it uses sequential I/O to do so, which makes it efficient.
- If Cassandra naively inserted values where they ultimately belonged, writing clients would pay for seeks upfront.
Tombstones
- An interesting case with Cassandra can be when we delete some data for a node that is down or unreachable, that node could miss a delete. When that node comes back online later and a repair occurs, the node could “resurrect” the data that had been previously deleted by re-sharing it with other nodes.
- To prevent deleted data from being reintroduced, Cassandra uses a concept called a tombstone Which is similar to a “soft delete” from the Relational databases world.
- When we delete data, Cassandra does not delete it right away, instead associates a tombstone with it, with a time to expiry.
- The purpose of this delay is to give a node that is unavailable time to recover.
- Tombstones are removed as part of compaction. During compaction, any row with an expired tombstone will not be propagated further.
Common Problems associated with Tombstones?
Tombstones make Cassandra’s writes efficient because the data is not removed right away when deleted. Instead, it is removed later during compaction.
Problems?
Slower Reads Indexes?
Cassandra uses clustering keys to create indexes of data within a partition.
These are only local indexes, not global indexes.
If you have many clustering keys in order to achieve multiple different sort orders, Cassandra will de-normalize the data such that it keeps two copies of it. Cassandra Pitfalls?
Lack of Strong Consistency even with Quorums(say Sloppy Quorum or hinted handoffs) which can create race conditions amongst concurrent writes.
Lack of ability to support data relationships(outside of sorting data within a partition)
Lack of Global Secondary Indexes if needed for Read Heavy applications where read cache may not work.
Summary
- Cassandra is Distributed, Decentralized(Leaderless), Scalable, Highly Available, Eventually Consistent NoSQL datastore.
- Was designed with Fault-Tolerance in mind(hardware/software failures can and do happen).
- Peer-to-Peer(Gossip) distributed System, with no Leader/Follower nodes. All nodes are equal except some are tagged seed nodes, for bootstrapping gossip to the nodes added to the cluster.
- Data is automatically Partitioned across nodes using Consistent Hashing as well as Replicated for Fault Tolerance and redundancy.
- Combines Distributed Nature of Amazon’s Dynamo(Consistent Hashing, Replication, Partitioning), with DataModel of Google’s BigTable, i.e. SSTable/MemTable.
- Offers Tunable Consistency(Default AP) but can be made strongly consistent(CP) but with performance implications.
- Uses Gossip protocol for Inter-Node communication.
- Supports Geographical Distribution of data across multiple clouds and data centers?
System Design Patterns Used?
- Consistent Hashing : Data Partitioning
- Quorum : Data Consistency
- Write Ahead Log : Durability
- Segmented Log: Splits its commit log into multiple smaller files instead of single large file for easier operation.
- Gossip Protocol: Membership or Cluster State information, Failure Detection?
- Phi Accrual Failure Detector: Adaptive Failure Detection using suspicion levels.
- Bloom Filters: Check for partition Key presence in SSTable(Read Optimized).
- Hinted Handoff: Sloppy Quorum?? and High Availability.
- Read Repair: Fix Stale values on Read?
References:
DataStax Docs
Cassandra Tombstone issues
BigTable
Dynamo
PhiAccrual Failure Detector(Akka) Open Questions?
What is a Murmer3 hashing function? How does it compare to MD5? Why Murmur?
Why 64 bit Token range? How does that compare to Dynamo?
R + W > Replication Factor can give Strong consistency levels in Cassandra?[Research]
What happens if the coordinator node which wrote the Hint on the local disk crashes? How does the hinted handoff process complete? [Research]
The latest write-timestamp is used as a marker for the correct version of data[Research?] in Cassandra? Conflict resolution? Last write wins or Vector Clocks? Data Loss?
Phi Accrual Failure Detector?
Write Ahead Log? Cassandra?
KeyCache and Row Cache in Cassandra? How is it used? How is it invalidated or kept in Sync?
Bloom Filters details?
Why is each compaction Strategy Size-Tiered or Levelled Compaction a good strategy for its corresponding workload?
Anti-Entropy in Cassandra?
Geographical replication of data?
Read up on Various company blogs on Cassandra?
Last Write Wins and Conflict Resolution?
Paper Link: https://www.cs.cornell.edu/projects/ladis2009/papers/lakshman-ladis2009.pdf
Last updated: March 15, 2026
Questions or discussion? Email me