Paper: Dynamo
Dynamo / Distributed Key Value Store
Problem: Design a distributed key-value store(or Distributed Hash Table) that is highly available (i.e., reliable), highly scalable, and completely decentralized.
Features
- Highly available Key-Value Store.
- Shopping Cart, Bestseller Lists, Sales Rank, Product Catalog, etc which needs only primary-key access to data.
- Multi-table RDBMS would limit scalability and availability.
- Can choose desired Level of Availability and Consistency.
Background?
- Designed for **high availability(**at a massive scale) and partition tolerance at the expense of strong consistency.
- Primary Motivation for being optimized for High Availability(Over consistency) was to be always up for serving customer requests to provide better customer experience.
- Dynamo design inspired various NoSQL Databases, Cassandra, Riak, VoldemortDB, DynamoDB.
Design Goals?
- Highly Available
- Reliability
- Highly Scalable
- Decentralized
- Eventually Consistent(EC) - Weaker Consistency model than Strong Consistency(Linearizability)
- (Notes: ) Latency Requirements?
- (Notes: ) Geographical Distribution of Data?
Use cases
- Dynamo can achieve strong consistency, but it comes with a performance impact. If Strong Consistency is a requirement, Dynamo is not the best option.
- Applications that need tight control over the trade-offs between availability, consistency, cost-effectiveness, and performance.
- Services that need only Primary Key access to the data.
System APIs:
- get(key) : T… Object, Context
- put(key, context, object)
- Dynamo treats both the object and the key as an arbitrary array of bytes (typically less than 1 MB).
- Uses MD5 Hashing algorithm on the key to generate 128-bit HashID, which is used to determine the storage nodes that are responsible for serving the key.
High Level Architecture
Agenda
- Data Distribution(Partitioning)
- Data Replication and Consistency
- Handing Temporary Failures(Fault Tolerance)
- Inter-Node communication(Unreliable Network) and Failure Detection
- High Availability
- Conflict resolution and handling permanent failures.
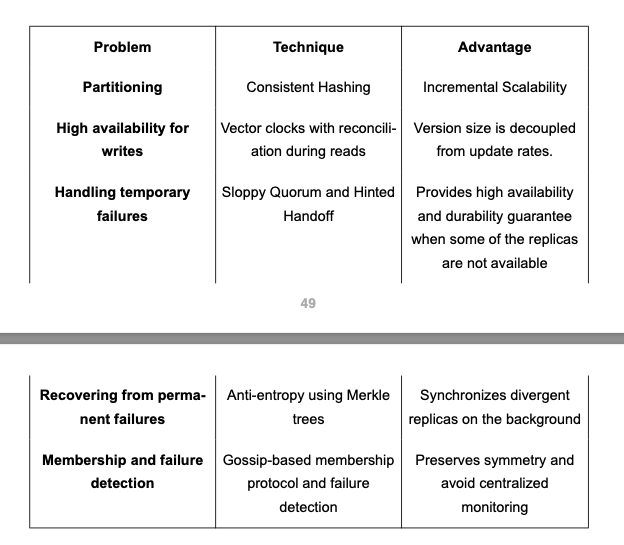
Data Partitioning
Distributing data across a set of nodes is called data partitioning.
Challenges with Partitioning?
Naive Approach(Modulo Hashing)
Better Approach(Consistent Hashing)
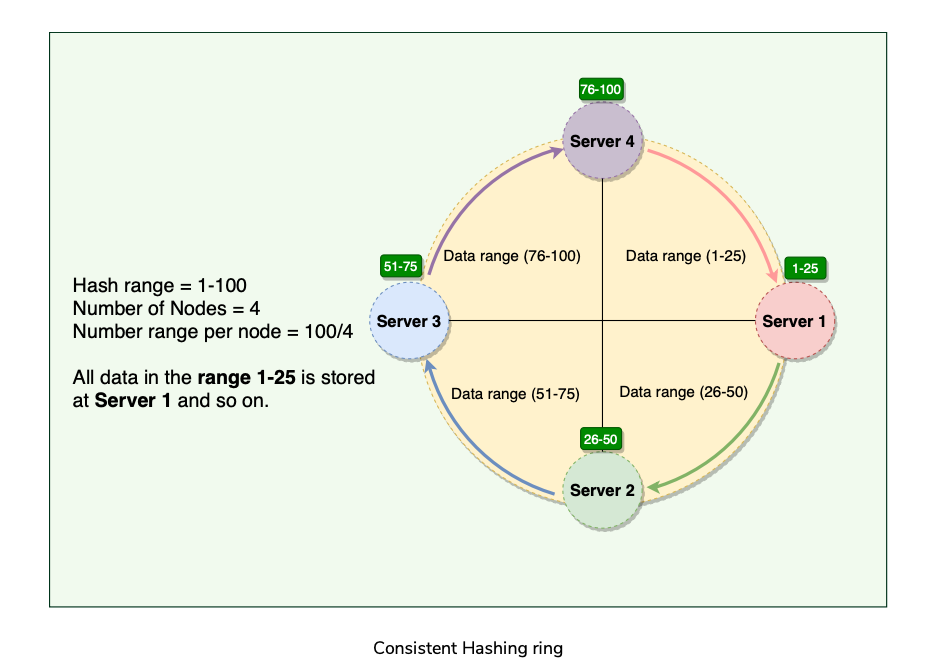
Consistent hashing represents the data managed by a cluster as a ring. The ring is divided into smaller predefined ranges. Each node in the ring is assigned a range of data. The start of the range is called a token(each node is assigned one token).
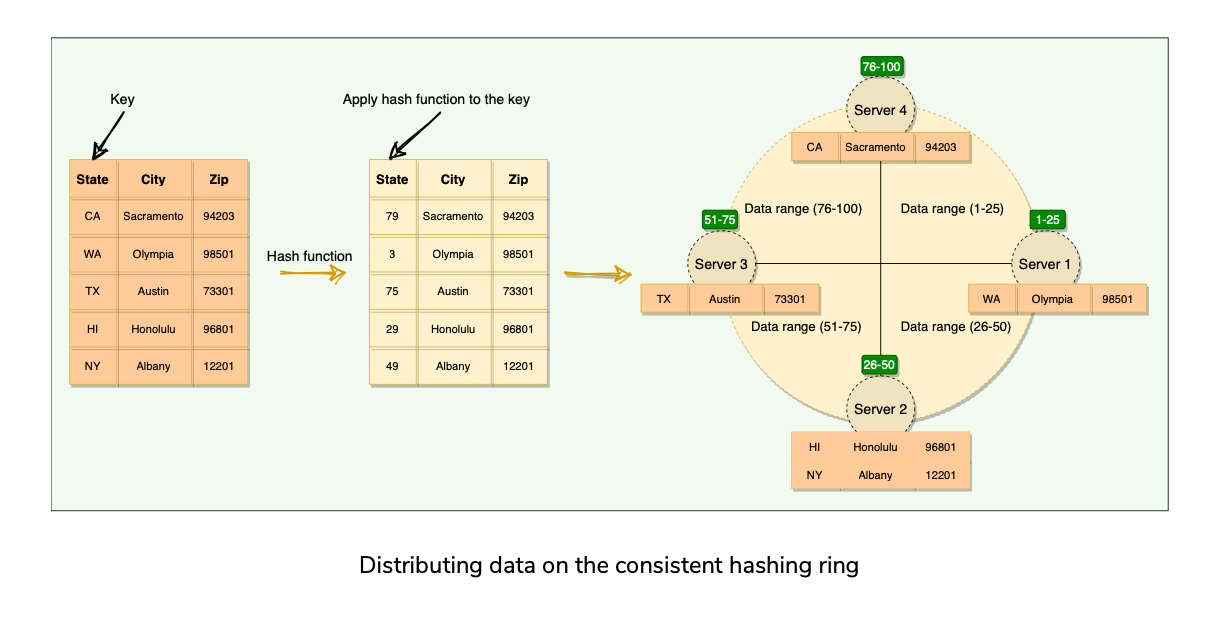
Above works great when a node is added or removed from the ring; as only the next node is affected in these scenarios
The basic Consistent Hashing algorithm assigns a single token (or a consecutive hash range) to each physical node and does a static division of ranges that requires calculating tokens based on a given number of nodes.
Dynamo efficiently handles these scenarios(node addition/removal) through the use of Virtual Nodes(or Vnodes). New scheme for distributing Tokens to physical nodes.
Instead of assigning a single token to a node, the hash range is divided into multiple smaller ranges, and each physical node is assigned multiple of these smaller ranges. Each of these subranges is called a Vnode.
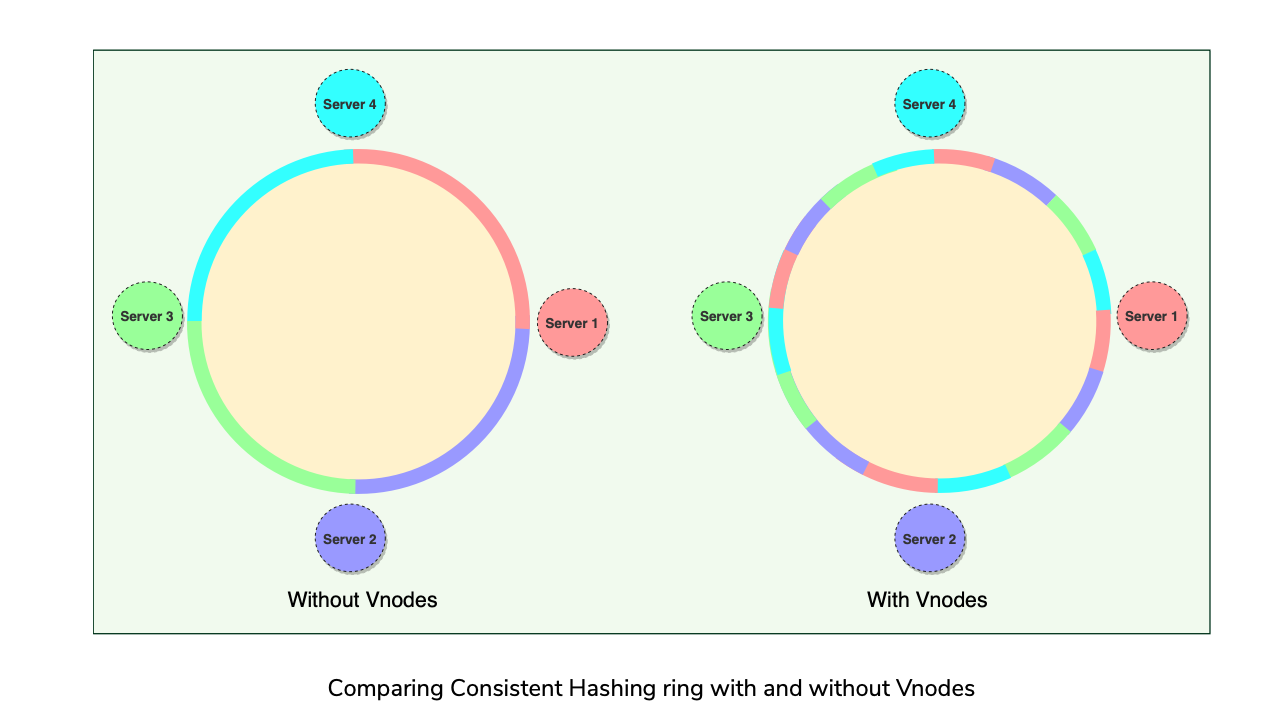
Vnodes are randomly distributed across the cluster and are generally non-contiguous so that no two neighboring Vnodes are assigned to the same physical node.
Nodes also carry replicas of other nodes for fault-tolerance.
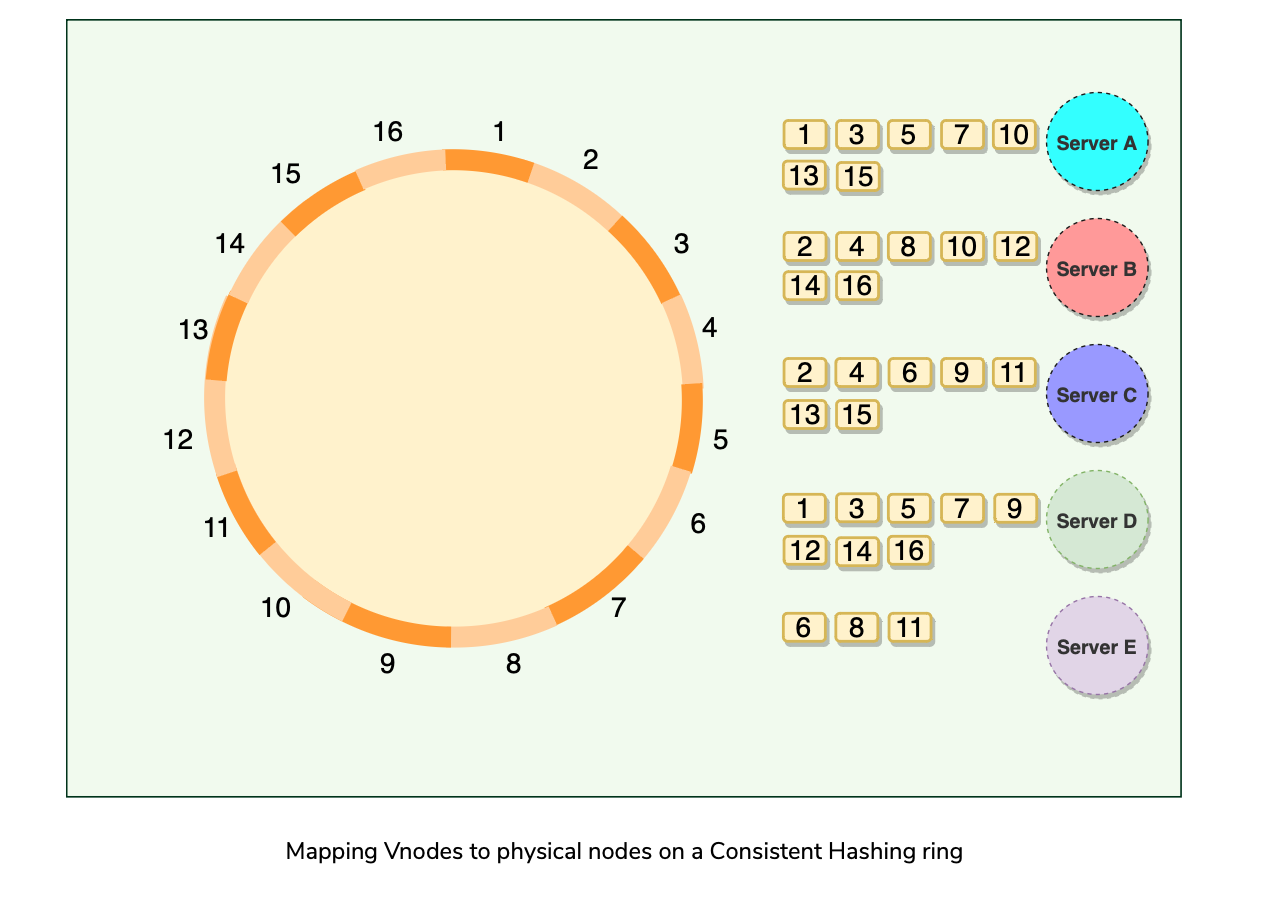
Since there can be heterogeneous machines in the clusters, some servers might hold more Vnodes than others.
Advantages of VNodes:
Data Replication
Agenda
Optimistic replication
Preference List
Sloppy Quorum and Handling of Temporary failures
Hinted Handoff Optimistic replication
Replicates each data item on N nodes(N = Replication Factor, configurable per Dynamo instance).
Each key is assigned a Coordinator node(node that falls first in the hash range), which stores the data locally and replicates asynchronously(What?? or Synchronously?) to N-1 Clockwise successor nodes in the ring(eventually consistent) called Optimistic replication.
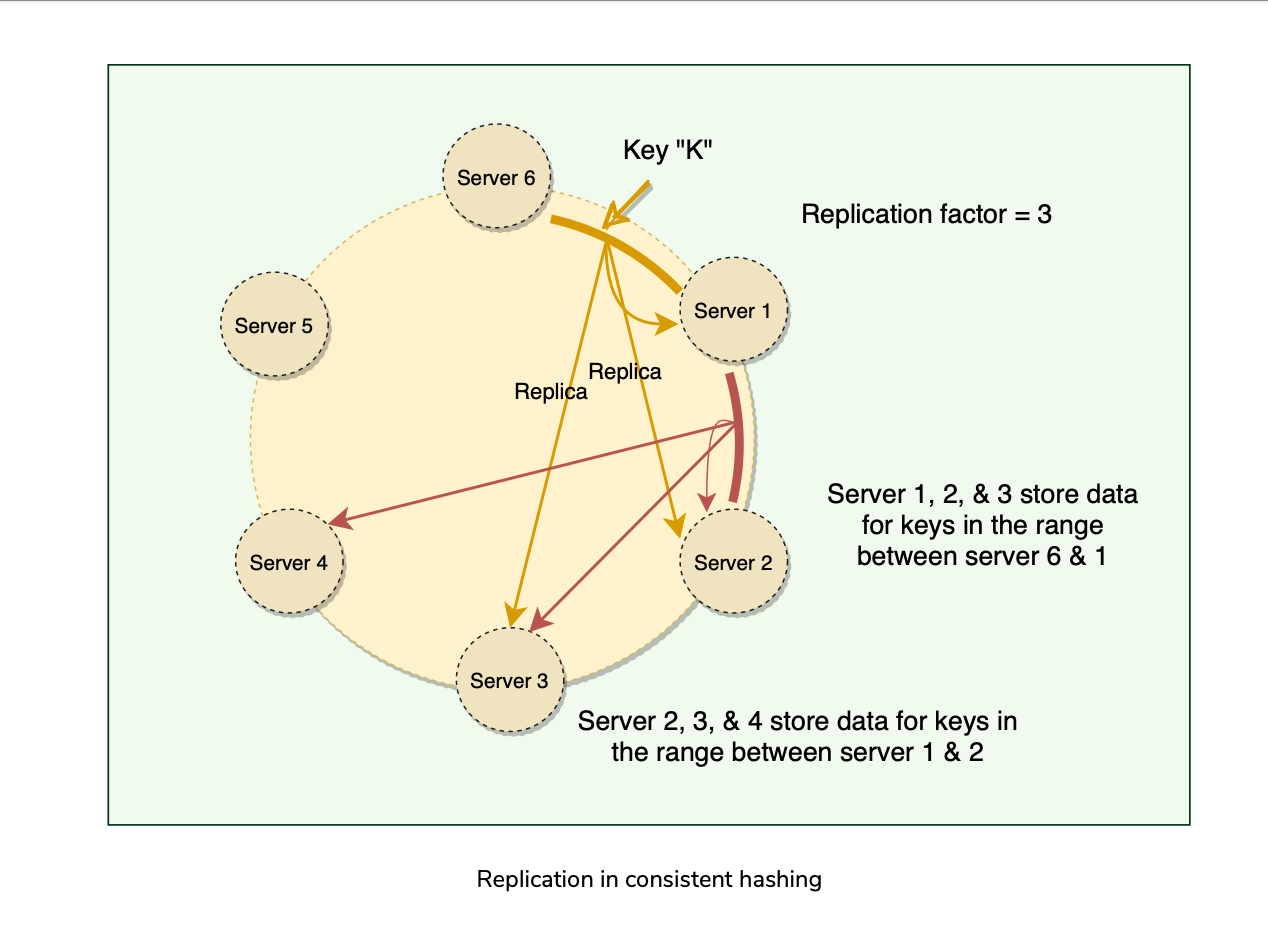
As Dynamo stores N copies of data spread across different nodes, if one node is down, other replicas can respond to queries for that range of data.
If a client cannot contact the coordinator node, it sends the request to a node holding a replica. Preference List
The list of nodes responsible for storing a particular key is called the preference list.
Dynamo is designed so that every node in the system can determine which nodes should be in this list for any specific key.
This list contains more than N nodes to account for failure and skip virtual nodes on the ring so that the list only contains distinct physical nodes. Sloppy Quorum and handling of temporary failures
Following traditional/strict quorum approaches, any distributed system becomes unavailable during server failures or network partitions and would have reduced availability even under simple failure conditions. Dynamo uses Sloppy Quorums.
With this approach, all read/write operations are performed on the first N healthy nodes from the preference list, which may not always be the first N nodes encountered while moving clockwise on the consistent hashing ring.
Fault Tolerance with Sloppy Quorum.
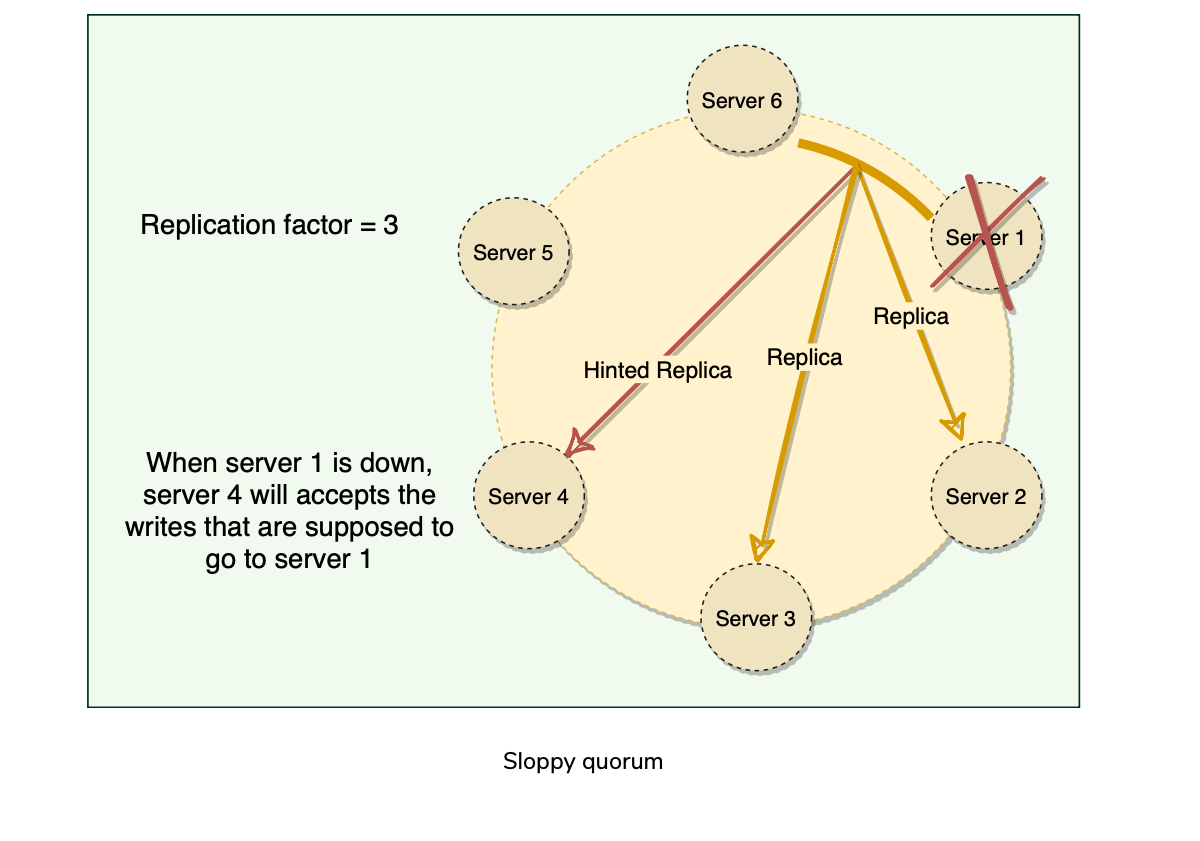
Hinted Handoff
Vector Clocks and Conflicting Data(Conflict Resolution)
Agenda:
Clock Skew?
Vector Clock?
Conflict Free Replicated Data Types(CRDTs)
Last Write Wins(LWW) Clock Skew
Physical clocks have clock skews, which is okay in single node systems, but can create concurrency updates in distributed systems, due to clock skews across different nodes.
Physical clocks are synchronized using NTP, but that still has skew, and 2 different nodes’ physical clocks can’t be accurately synchronized.
Using special hardware like GPS clocks and Atomic Clocks can reduce the clock skews, but doesn’t entirely eliminate it.
Physical clock has a problem with Causal Ordering of events(happens-before relationship). Vector Clock?
Captures Causal ordering between events.
Vector clock is a (node, counter) pair. What? Isn’t it Lamport Clocks?
Vector timestamps are attached to every version of the object stored in Dynamo.
One can determine whether two versions of an object are on parallel branches or have a causal ordering by examining their vector clocks.
If the counters on the first object’s clock are less-than-or-equal to all of the nodes in the second clock, then the first is an ancestor of the second and can be forgotten. Otherwise, the two changes are considered to be in conflict and require reconciliation. Dynamo resolves these conflicts at read-time.
Version branching may happen in the presence of failures combined with concurrent updates, resulting in conflicting versions of an object.
Dynamo truncates vector clocks (oldest first) when they grow too large. If Dynamo ends up deleting older vector clocks that are required to reconcile an object’s state, Dynamo would not be able to achieve eventual consistency. Conflict Free Replicated Data Types?
To make use of CRDTs, we need to model our data in such a way that concurrent changes can be applied to the data in any order and will produce the same end result. This way, the system does not need to worry about any ordering guarantees.
The idea that any two nodes that have received the same set of updates will see the same end result is called strong eventual consistency. Last Write Wins
Dynamo(and Cassandra) also offer a way to do server side conflict resolution, LWW.
Uses Physical(Wall Clock/Time-Of-the-Day) Clocks.
Can potentially lead to Data-Loss during concurrent writes.
Life of Dynamo’s put() and get() operations.
Agenda:
- Strategies for Coordinator selection
- Consistency protocol
- put() process
- get() process
- Request handling through a state machine.
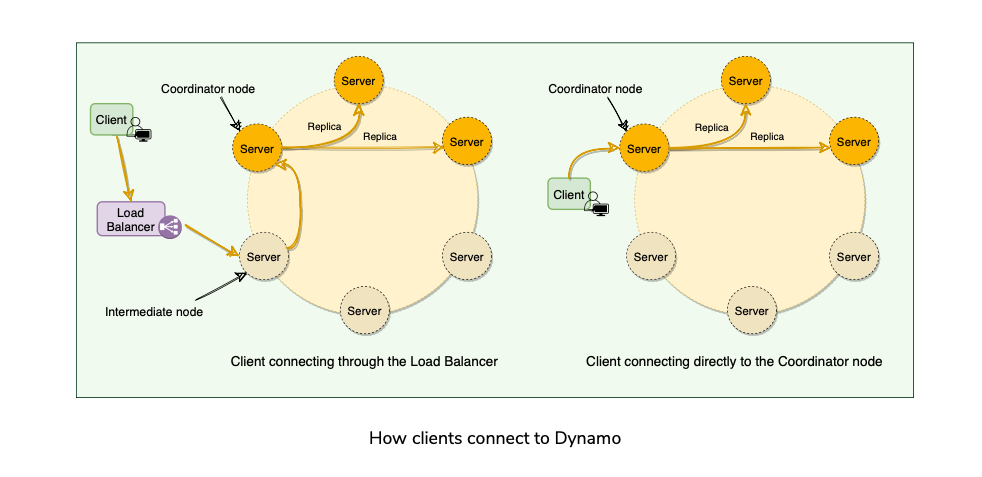
Strategies for choosing coordinator
- Clients route request using Generic Load Balancer.
- Clients use a partition-aware client library that routes requests to the appropriate coordinator with lower latency.
Consistency Protocol
Uses a consistency protocol similar to quorum systems.
R + W > N ( R /W = minimum number of nodes to participate in Read/Write)
Common configurations(N, R, W) for Dynamo (3, 2, 2)
Latency of get() and put() depends upon the slowest of replicas. Put() Process
Coordinator generates new data version and vector timestamp.
Saves data locally.
Sends write requests to N-1 highest ranked healthy nodes from the preference list.
Put() is considered successful after receiving W-1 confirmations. Get() process
Coordinator requests the data version from N-1 highest ranked healthy nodes from the preference list.
Waits until R - 1 replies.
Coordinator handles causal data versioning using vector clocks/timestamps.
Returns all data versions to the caller.
Request handling through the state machine
- Each client request results in creating a state machine on the node that received the client request.
- The state machine contains all the logic for
- Each state machine instance handles exactly one client request.
- A read operation implements following state machine:
- Writes:
Anti-Entropy through Merkle Trees
Dynamo uses Vector clocks to remove write conflicts(Read Repair) while serving read requests if it receives stale responses from some of the replicas.
If a replica fell significantly behind others, it might take a very long time to resolve conflicts using read repair(vector clocks), depending upon if those keys were read or not. It may happen that some of the keys are never accessed, and they cold remain stale for longer.
We need a mechanism to automatically reconcile replicas in the background(and do conflict resolution if any).
To do this, we need to quickly compare two copies of a range of data residing on different replicas and figure out exactly which parts are different.
Naively splitting up the entire data range for checksums is not very feasible; there is simply too much data to be transferred.(Transferred? How?)
Dynamo uses Merkle trees to compare replicas of a range.
A Merkle tree is a binary tree of hashes, where each internal node is the hash of its two children, and each leaf node is a hash of a portion of the original data.
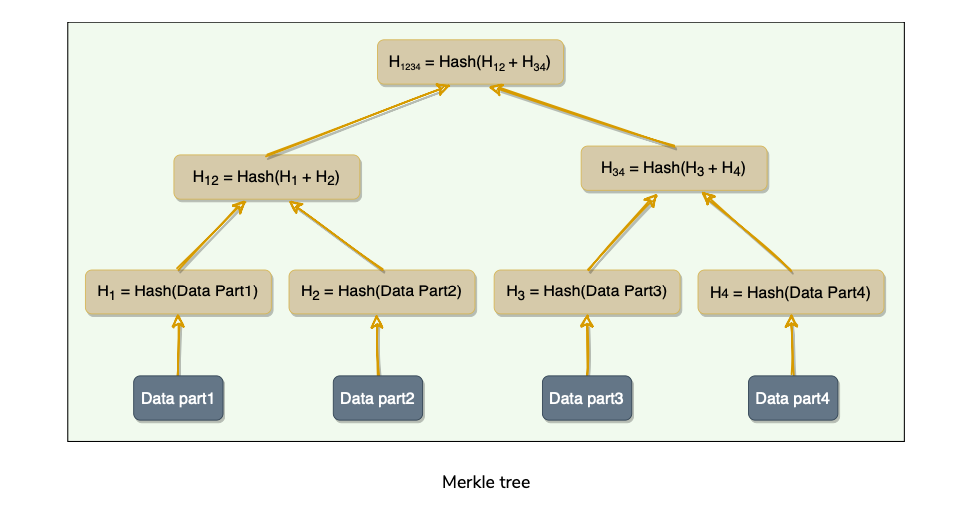
Now comparing the ranges of data on two replicas is equivalent to comparing two Merkle Trees
The principal advantage of using a Merkle tree is that each branch of the tree can be checked independently without requiring nodes to download the entire tree or the whole data set.
Merkle trees minimize the amount of data that needs to be transferred for synchronization and reduce the number of disk reads performed during the anti-entropy process.
The disadvantage of using Merkle trees is that many key ranges can change when a node joins or leaves, and as a result, the trees need to be recalculated.
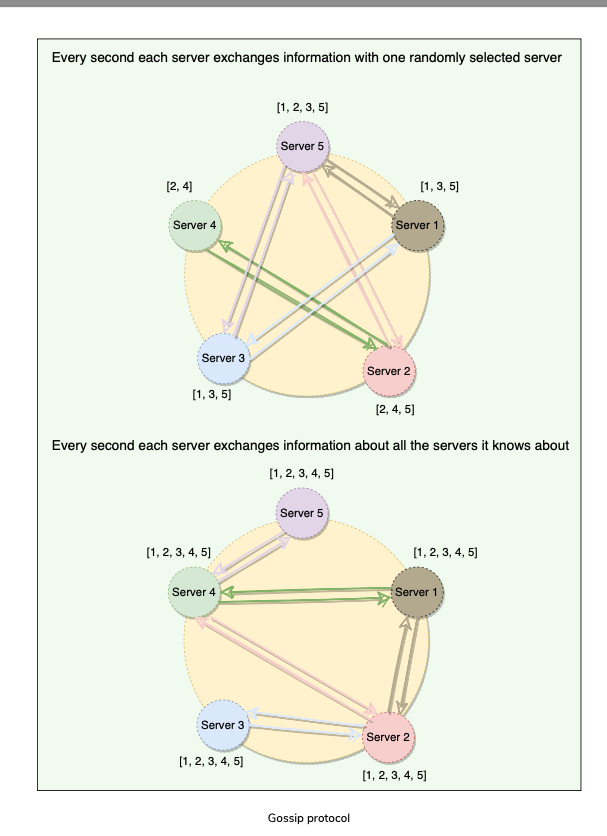
Gossip Protocol
What is a Gossip Protocol?
- How does Node Failure Detection happen in Dynamo?
- Since we do not have any central node that keeps track of all nodes to know if a node is down or not, how does a node know every other node’s current state?
- Naive Approach: Each Node broadcast HeatBeat message to every other Node
- Optimized Approach: Gossip Protocol
External Discovery Through Seed Nodes?
- Dynamo nodes use gossip protocol to find the current state of the ring. This can result in a logical partition of the cluster in a particular scenario.
- An administrator joins node A to the ring and then joins node B to the ring. Nodes A and B consider themselves part of the ring, yet neither would be immediately aware of each other. To prevent these logical partitions, Dynamo introduced the concept of seed nodes.
- Seed nodes are fully functional nodes and can be obtained either from a static configuration or a configuration service. This way, all nodes are aware of seed nodes.
- Each node communicates with seed nodes through gossip protocol to reconcile membership changes; therefore, logical partitions are highly unlikely.
Characteristics and Criticism of Dynamo
Responsibilities of a Dynamo Node
- Managing get() and put() requests via acting as a Coordinator(or request Forwarder).
- Keeping track of membership(Hash ranges in a Ring) and detecting failures(Gossip)
- Local Persistent Storage
Characteristics of Dynamo
- Distributed(Can run across several machines)
- Decentralized(No external coordinator, all nodes identical)
- Scalable(Horizontally scaled on commodity hardware with Fault Tolerance. No Manual intervention/rebalancing required)
- Highly Available
- Fault Tolerant and Reliable
- Tunable Consistency(Trade Offs b/w Availability and Consistency by adjusting the replication factor 3,2,2, or 3,1,3, or 3,3,1 etc).
Criticism on Dynamo Design?
- Each Dynamo node contains the entire routing table. Could affect scalability of the system as this routing table gets larger as more nodes are added to the system.
- Dynamo seems to imply that it strives for symmetry(all nodes have the same set of responsibilities). But it does specify some nodes as seed nodes for external discovery to avoid logical partition. May violate Dynamo’s symmetry principle.
- DHTs can be susceptible to Several different types of attack?[Research More?]
- Dynamo’s design can be described as a Leaky Abstraction.
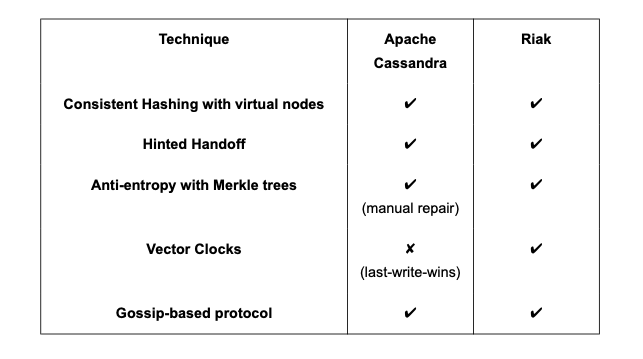
DataStores developed on Principles of Dynamo
- Riak is a distributed NoSQL key-value data store that is highly available, scalable, fault-tolerant, and easy to operate.
- Cassandra is a distributed, decentralized, scalable, and highly available NoSQL wide-column database.
Summary
Paper reading Video.
References:
https://www.allthingsdistributed.com/2007/10/amazons_dynamo.html
https://research.google/pubs/bigtable-a-distributed-storage-system-for-structured-data/
https://www.allthingsdistributed.com/2012/01/amazon-dynamodb.html
https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type
https://www.allthingsdistributed.com/2017/10/a-decade-of-dynamo.html
https://news.ycombinator.com/item?id=915212 Open Questions:
Anti-Entropy and Merkle Trees
DHTs can be susceptible to Several different types of attack?[Research More?]
Underlying storage for Dynamo store. Berkeley, in-memory + persistent + more.
Why does it use MD5 hashing? Why not something else?
Logical partitioning and seed nodes?
New Features and revision in the design?
Paper Link: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
Last updated: March 15, 2026
Questions or discussion? Email me