Paper: DynamoDB
DynamoDB
Summary/Abstract
- Amazon DynamoDB is a NoSQL cloud database service that provides consistent performance at any scale.
- Fundamental properties: consistent performance, availability, durability, and a fully managed serverless experience.
- In 2021, during the 66-hour Amazon Prime Day shopping event, 89.2 million requests per second, while experiencing high availability with single-digit millisecond performance.
- Design and implementation of DynamoDB have evolved since the first launch in 2012. The system has successfully dealt with issues related to fairness, traffic imbalance across partitions, monitoring, and automated system operations without impacting availability or performance.
Introduction
- The goal of the design of DynamoDB is to complete all requests with low single-digit millisecond latencies.
- DynamoDB uniquely integrates the following six fundamental system properties:
- DynamoDB is a fully managed cloud service.
- DynamoDB employs a multi-tenant architecture.
- DynamoDB provides predictable performance
- DynamoDB is highly available.
- DynamoDB supports flexible use cases.
- DynamoDB evolved as a distributed database service to meet the needs of its customers without losing its key aspect of providing a single-tenant experience to every customer using a multi-tenant architecture.
- The paper explains the challenges faced by the system and how the service evolved to handle those challenges while connecting the required changes to a common theme of durability, availability, scalability, and predictable performance.
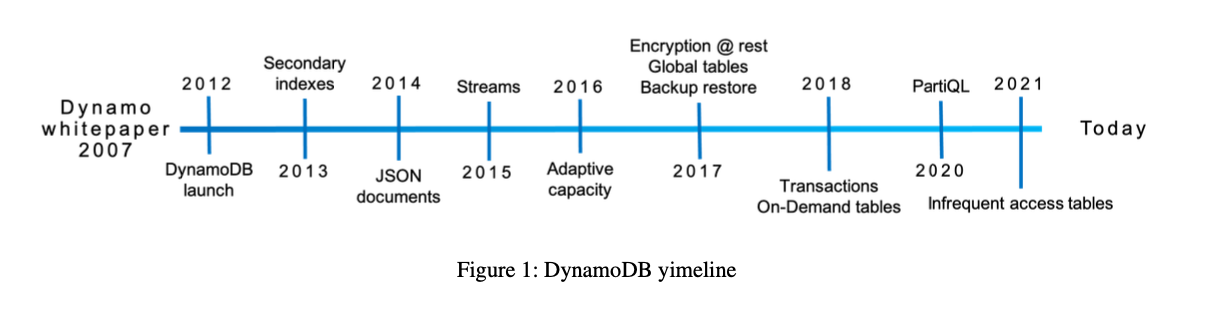
History
- Design of DynamoDB was motivated by our experiences with its predecessor Dynamo. Dynamo was created in response to the need for a highly scalable, available, and durable key-value database for shopping cart data
- Amazon learned that providing applications with direct access to traditional enterprise database instances led to scal- ing bottlenecks such as connection management, interference between concurrent workloads, and operational problems with tasks such as schema upgrades.
- Service Oriented Architecture was adopted to encapsulate an application’s data behind service-level APIs that allowed sufficient decoupling to address tasks like reconfiguration without having to disrupt clients.
- DynamoDB took the principles from Dynamo(which was being run as Self-hosted DB but created operational burden for developers) & Simple DB, a fully managed elastic NoSQL database service, but the data model couldn’t scale to the demands of the large Tables which DDB needed.
- Dynamo Limitations:
- SimpleDB limitations:
- Amazon concluded that a better solution would combine the best parts of the original Dynamo design (incremental scalability and predictable high performance) with the best parts of SimpleDB (ease of administration of a cloud service, consistency, and a table-based data model that is richer than a pure key-value store)
Architecture
A DynamoDB table is a collection of items.
Each item is a collection of attributes. Uniquely identified by a primary key.
Schema of the primary key is specified at the table creation time.
The partition key’s value is always used as an input to an internal hash function.
The output from the hash function and the sort key value (if present) determines where the item will be stored.
Multiple items can have the same partition key value in a table with a composite primary key. However, those items must have different sort key values.
Supports secondary indexes to provide enhanced querying capability, which allows querying the data in the table using an alternate key.
DynamoDB provides a simple interface to store or retrieve items from a table or an index.

DynamoDB supports ACID transactions for multi-item updates w/o affecting scalability/availability/performance.
A DynamoDB table is divided into multiple partitions.
Each partition of the table hosts a disjoint and contiguous part of the table’s key-range and has multiple replicas(replication Group) distributed across different Availability Zones for high availability and durability.
The Replication Group uses Multi-Paxos for leader election and consensus.
Any replica can trigger a round of the election.
Once elected leader, a replica can maintain leadership as long as it periodically renews its leadership lease.
Only the leader replica can serve write and strongly consistent read requests.
Leader generates a write-ahead log record and sends it to its peers.
Write is acknowledged to the application once a quorum of peers persists the log record to their local write-ahead logs.
DynamoDB supports strong(Leader Read) and eventually consistent(Replica read) reads.
The leader of the group extends its leadership using a lease mechanism.
If the leader of the group is detected as a failure (considered unhealthy or unavailable) by any of its peers, the peer can propose a new round of the election to elect itself as the new leader. The new leader won’t serve any writes or consistent reads until the previous leader’s lease expires.
Partitioning/Replication Group
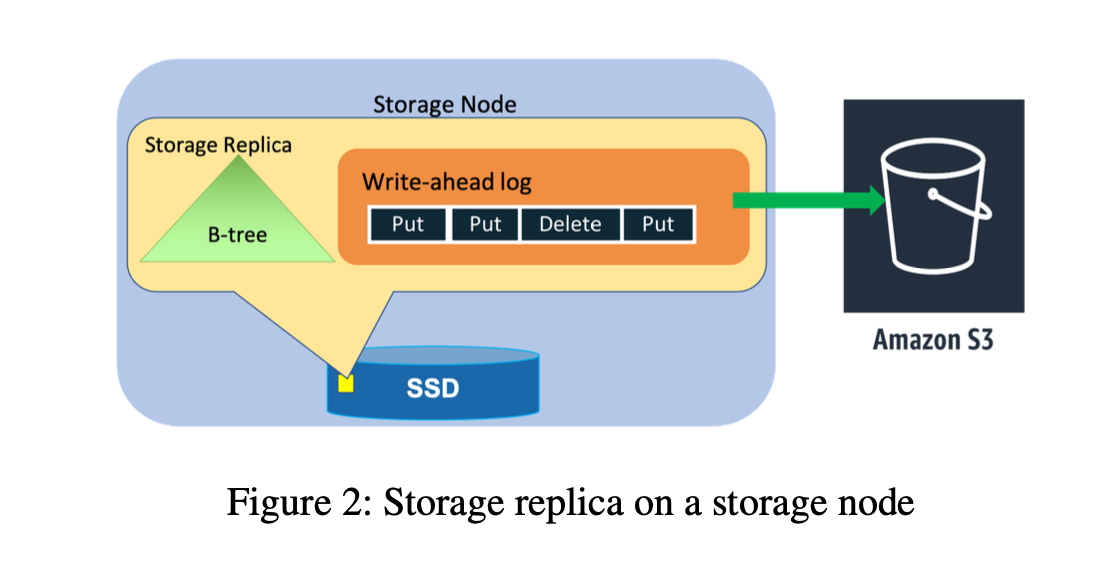
Log Replica/Node - Write Ahead Log(replicated) for High Availability and Durability.
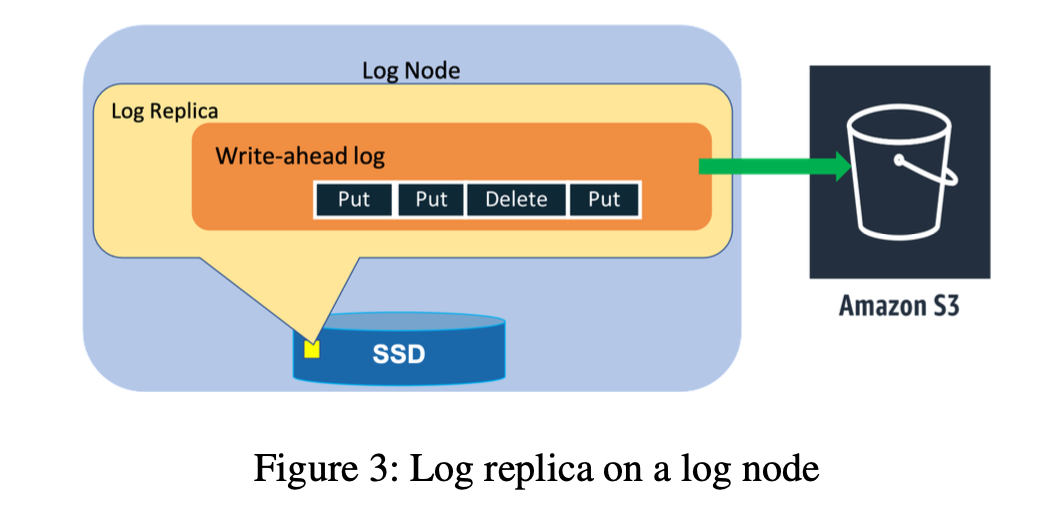
Multi-Paxos Leader Election and Consensus.
Writes and Strongly/Eventually Consistent Reads
Microservice architecture
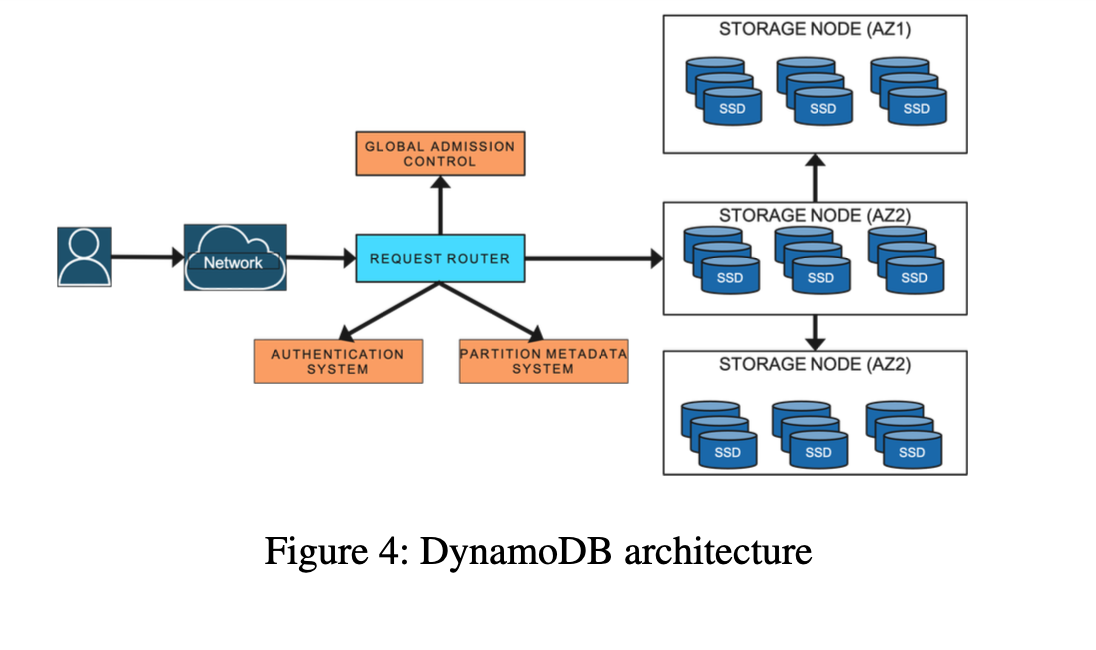
Metadata Service
Request Router Service
Auto-Admin Service(Central Nervous System of DDB)
Storage Service
Features supported by other Services
Journey from Provisioned to On-Demand
DDB was launched with Partitions as an internal abstraction, as a way to dynamically scale both the capacity and performance of tables.
Customers explicitly specified the throughput that a table required in terms of read capacity units (RCUs) and write capacity units (WCUs). RCUs and WCUs collectively are called provisioned throughput.
As the demands from a table changed (because it grew in size or because the load increased), partitions could be further split and migrated to allow the table to scale elastically. Partition abstraction proved to be really valuable and continues to be central to the design of DynamoDB.
[Challenge] This early version tightly coupled the assignment of both capacity and performance to individual partitions, which led to challenges
DynamoDB uses admission control to ensure that storage nodes don’t become overloaded, to avoid interference between co-resident table partitions, and to enforce the throughput limits requested by customers.
Admission control was the shared responsibility of all storage nodes for a table. Storage nodes independently performed admission control based on the allocations of their locally stored partitions.
Allocated throughput of each partition was used to isolate the workloads. DynamoDB enforced a cap on the maximum throughput that could be allocated to a single partition. Total throughput of all the partitions hosted by a storage node is less than or equal to the maximum allowed throughput on the node as determined by the physical characteristics of its storage drives.
The throughput allocated to partitions was adjusted when the overall table’s throughput was changed or its partitions were split into child partitions.
When a partition was split for size, the allocated throughput of the parent partition was equally divided among the child partitions and was allocated based on the table’s provisioned throughput.
E.g. Assume that a partition can accommodate a maximum provisioned throughput of 1000 WCUs. When a table is created with 3200 WCUs, DynamoDB created four partitions that each would be allocated 800 WCUs. If the table’s provisioned throughput was increased to 3600 WCUs, then each partition’s capacity would increase to 900 WCUs. If the table’s provisioned throughput was increased to 6000 WCUs, then the partitions would be split to create eight child partitions, and each partition would be allocated 750 WCUs. If the table’s capacity was decreased to 5000 WCUs, then each partition’s capacity would be decreased to 675 WCUs
The uniform distribution of throughput across partitions is based on the assumptions that an application uniformly accesses keys in a table and the splitting a partition for size equally splits the performance.
However, it was discovered that application workloads frequently have non-uniform access patterns both over time and over key ranges.
Hot Partition Worsening with Split: When the request rate within a table is non-uniform, splitting a partition and dividing performance allocation proportionately can result in the hot portion of the partition having less available performance than it did before the split.
[Single Hot Partition] Since throughput was allocated statically and enforced at a partition level, these non-uniform workloads occasionally resulted in an application’s reads and writes being rejected, called throttling, even though the total provisioned throughput of the table was sufficient to meet its needs. Common Challenges faced by the applications were:
Hot Partition
Throughput Dilution.
Customers would increase the provisioned throughput of the table(even if they were under the limit overall), which caused poor performance. It was difficult to estimate the correct provisioned throughput.
Hot partitions and throughput dilution stemmed from tightly coupling a rigid performance allocation to each partition, and dividing that allocation as partitions split. Bursting and Adaptive Capacity to address these concerns.
Improvements to Admission Control:
Key Observations:
- Partitions had non-uniform access/traffic.
- Not all partitions hosted by a storage node used their allocated throughput simultaneously.
Bursting
- The idea behind Bursting was to let applications tap into the unused capacity at a partition level on a best effort basis to absorb short-lived spikes.
- DynamoDB retained a portion of a partition’s unused capacity for later bursts of throughput usage for up to 300 seconds and utilized it when consumed capacity exceeded the provisioned capacity of the partition.
- DynamoDB still maintained workload isolation by ensuring that a partition could only burst if there was unused throughput at the node level. The capacity was managed on the storage node using multiple token buckets to provide admission control:
- **[Partition Token + Node Token]**When a read or write request arrives on a storage node, if there were tokens in the partition’s allocated token bucket, then the request was admitted and tokens were deducted from the partition and node level bucket.
- [Burst Token + Node Token] Once a partition had exhausted all the provisioned tokens, requests were allowed to burst only when tokens were available both in the burst token bucket and the node level token bucket.
- Read requests were accepted based on the local token buckets.
- [Replica node’s Token Bucket for Write] Write requests using burst capacity require an additional check on the node-level token bucket of other member replicas of the partition.
- The leader replica of the partition periodically collected information about each of the members node-level capacity.
Adaptive Capacity
- DynamoDB launched adaptive capacity to better absorb long-lived spikes that cannot be absorbed by the burst capacity.
- Better absorb work-loads that had heavily skewed access patterns across partitions.
- Adaptive capacity actively monitored the provisioned and consumed capacity of all the tables.
- If a table experienced throttling and the table level throughput was not exceeded, then it would automatically increase (boost) the allocated throughput of the partitions of the table using a proportional control algorithm.
- The autoadmin system ensured that partitions receiving boost were relocated to an appropriate node that had the capacity to serve the increased throughput, however like bursting, adaptive capacity was also best-effort but eliminated over 99.99% of the throttling due to skewed access pattern.
Global Admission Control
- Even though Bursting and Adaptive Capacity significantly reduced throughput problems for non-uniform access, they had limitations.
- Takeaway from bursting and adaptive capacity was that we had tightly coupled partition level capacity to admission control.
- Admission control was distributed and performed at a partition level.
- DynamoDB realized it would be beneficial to remove admission control from the partition and let the partition always burst while providing workload isolation.
- DynamoDB replaced adaptive capacity with global admission control (GAC).
- GAC builds on the same idea of Token Bucket.
- The GAC service centrally tracks the total consumption of the table capacity in terms of tokens.
- Each request router maintains a local token bucket to make admission decisions and communicates with GAC to replenish tokens at regular intervals (in the order of a few seconds).
- [Important Design Consideration] Each GAC server can be stopped and restarted without any impact on the overall operation of the service.
- Each GAC server can track one or more token buckets configured independently.
- All the GAC servers are part of an independent hash ring.
- Request routers manage several time-limited tokens locally. When a request from the application arrives, the request router deducts tokens. Eventually, the request router will run out of tokens because of consumption or expiry. When the request router runs off of tokens, it requests more tokens from GAC.
- The GAC instance uses the information provided by the client to estimate the global token consumption and vends tokens available for the next time unit to the client’s share of overall tokens.
- Thus, it ensures that non-uniform workloads that send traffic to only a subset of items can execute up to the maximum partition capacity.
- In addition to the global admission control scheme, the partition-level token buckets were retained for defense in-depth. The capacity of these token buckets is then capped to ensure that one application doesn’t consume all or a significant share of the resources on the storage nodes.
Balancing Consumed Capacity
- Letting partitions burst(always) required DynamoDB to manage burst capacity effectively.
- Colocation was a straightforward problem with provisioned throughput tables because of static partitions.
Splitting for Consumption
- [Problem] Even with GAC and the ability for partitions to always burst, tables could experience throttling if their traffic was skewed to a specific set of items.
- [Solution]
- DynamoDB automatically scales out partitions once the consumed throughput of a partition crosses a certain threshold.
- The split point in the key range is chosen based on key distribution the partition has observed.
- The observed key distribution serves as a proxy for the application’s access pattern and is more effective than splitting the key range in the middle.
- Partition splits usually complete in the order of minutes.
- [Catch] Still class of workloads exist that cannot benefit from split for consumption. E.g. a partition receiving high traffic to a single item or a partition where the key range is accessed sequentially will not benefit from split. DDB avoids splitting the partition.
On Demand Provisioning
- [Context]
- Initially, applications migrated to DDB, were on self provisioned servers either on-prem or on self-hosted databases.
- DynamoDB provides a simplified serverless operational model and a new model for provisioning - read and write capacity units.
- [Problem]
- The concept of capacity units was new to customers, some found it challenging to forecast the provisioned throughput.
- Customers either over provisioned(Low utilization) or under provisioned(Throttling).
- [Solution] To improve the customer experience for spiky workloads, DDB launched On-Demand Tables.
- DynamoDB provisions the on-demand tables based on the consumed capacity by collecting the signal of reads and writes and instantly accommodates up to double the previous peak traffic on the table.
- On-demand scales a table by splitting partitions for consumption. The split decision algorithm is based on traffic.
- GAC allows DynamoDB to monitor and protect the system from one application consuming all the resources.
Durability and Correctness
- Data loss can occur because of hardware failures, software bugs, or hardware bugs.
- DynamoDB is designed for high durability by having mechanisms to prevent, detect, and correct any potential data losses.
Hardware Failures
- Write-ahead logs(WAL) in DynamoDB are central for providing durability and crash recovery. Write ahead logs are stored in all three replicas of a partition.
- For higher durability, the write ahead logs are periodically archived to S3, an object store that is designed for 11 nines(99.999999999) of durability.
- The unarchived logs are typically a few hundred megabytes in size.
- When a node fails, all replication groups hosted on the node are down to two copies.
- The process of healing a storage replica can take several minutes because the repair process involves copying the B-tree and write-ahead logs.
- [Solution] Upon detecting an unhealthy storage replica, the leader of a replication group adds a log replica to ensure there is no impact on durability.
- Adding a log replica takes only a few seconds because the system has to copy only the recent write-ahead logs from a healthy replica to the new replica without the B-tree. Quick healing of impacted replication groups using log replicas ensures high durability of most recent writes.
Silent Data Errors
- [Problem] Some hardware failures can cause incorrect data to be stored . These errors can happen because of the storage media, CPU, or memory.
- It’s very difficult to detect these and they can happen anywhere in the system.
- [Solution] DynamoDB makes extensive use of checksums to detect silent errors.
- By maintaining checksums within every log entry, message, and log file, DynamoDB validates data integrity for every data transfer between two nodes.
- Checksums serve as guardrails to prevent errors from spreading to the rest of the system.
- Every log file that is archived to S3 has a manifest that contains information about the log, such as a table, partition and start and end markers for the data stored in the log file.
- The agent responsible for archiving log files to S3 performs various checks before uploading the data. These include and are not limited to verification of every log entry to ensure that it belongs to the correct table and partition, verification of checksums to detect any silent errors, and verification that the log file doesn’t have any holes in the sequence numbers.
- Once all the checks are passed, the log file and its manifest are archived. Log archival agents run on all three replicas of the replication group. If one of the agents finds that a log file is already archived, the agent downloads the uploaded file to verify the integrity of the data by comparing it with its local write-ahead log.
- Every log file and manifest file are uploaded to S3 with a content checksum. The content checksum is checked by S3 as part of the put operation, which guards against any errors during data transit to S3.
Continuous Verification
- DynamoDB also continuously verifies data at rest. Our goal is to detect any silent data errors or bit rot in the system. An example of such a continuous verification system is the scrub process.
- The goal of scrub is to detect errors that we had not anticipated, such as bit rot.
- The scrub process runs and verifies two things:
- The verification is done by computing the checksum of the live replica and matching that with a snapshot of one generated from the log entries archived in S3.
- Scrub acts as a defense in depth to detect divergences between the live storage replicas with the replicas built using the history of logs from the inception of the table.
- A similar technique of continuous verification is used to verify replicas of global tables.
- We have learned that continuous verification of data-at-rest is the most reliable method of protecting against hardware failures, silent data corruption, and even software bugs.
Software Bugs
- [Problem] DDB is a complex Distributed Key Value store. High complexity increases the probability of human error in design, code, and operations. Errors in the system could cause loss or corruption of data, or violate other interface contracts that our customers depend on.
- [Solution] DDB uses formal methods extensively to ensure the correctness of our replication protocols. The core replication protocol was specified using TLA+.
- When new features that affect the replication protocol are added, they are incorporated into the specification and model checked.
- Model checking has allowed us to catch subtle bugs that could have led to durability and correctness issues before the code went into production. S3 also uses Model Checking.
- Extensive failure injection testing and stress testing to ensure the correctness of every piece of software deployed.
- In addition to testing and verification of the replication protocol of the data plane, formal methods have also been used to verify the correctness of our control plane and features such as distributed transactions.
Backups and Restore
- In addition to guarding against physical media corruption, DynamoDB also supports backup and restore to protect against any logical corruption due to a bug in a customer’s application. Backups or restores don’t affect performance or availability of the table as they are built using the write-ahead logs that are archived in S3.
- The backups are consistent across multiple partitions up to the nearest second.
- The backups are full copies of DynamoDB tables and are stored in an Amazon S3 bucket.
- DynamoDB also supports point-in-time restore where customers can restore the contents of a table that existed at any time in the previous 35 days to a different DynamoDB table in the same region.
- For tables with the point-in-time restore enabled, DynamoDB creates periodic(based on the amount of write-ahead logs accumulated for the partition) snapshots of the partitions that belong to the table and uploads them to S3.
- Snapshots, in conjunction to write-ahead logs, are used to do point-in-time restore.
- [Workflow] When a point-in-time restore is requested for a table,
Availability
- To achieve high availability, DynamoDB tables are distributed and replicated across multiple Availability Zones (AZ) in a Region. DynamoDB regularly tests resilience to node, rack, and AZ failures.
- To test the availability and durability of the overall service, power-off tests are exercised. Using realistic simulated traffic, random nodes are powered off using a job scheduler. At the end of all the power-off tests, the test tools verify that the data stored in the database is logically valid and not corrupted.
Write and Consistent Read Availability
- A partition’s write availability depends on its ability to have a healthy leader and a healthy write quorum.
- A healthy write quorum in the case of DynamoDB consists of two out of the three replicas from different AZs.
- A partition remains available as long as there are enough healthy replicas for a write quorum and a leader
- A partition will become unavailable for writes if the number of replicas needed to achieve the minimum quorum are unavailable
- The leader replica serves consistent reads.
- Introducing log replicas was a big change to the system, and the formally proven implementation of Paxos provided us the confidence to safely tweak and experiment with the system to achieve higher availability
- Eventually consistent reads can be served by any of the replicas.
- In case a leader replica fails, other replicas detect its failure and elect a new leader to minimize disruptions to the availability of consistent reads.
Failure Detection
- [Problem] A newly elected leader will have to wait for the expiry of the old leader’s lease before serving any traffic. While this only takes a couple of seconds, the elected leader cannot accept any new writes or consistent read traffic during that period, thus disrupting availability.
- Failure detection must be quick and robust to minimize disruptions. False positives in failure detection can lead to more disruptions in availability. Failure detection works well for failure scenarios where every replica of the group loses connection to the leader.
- However, nodes can experience gray network failures(Gray Failure).
- Gray network failures can happen because of communication issues between a leader and follower, issues with outbound or inbound communication of a node, or front-end routers facing communication issues with the leader even though the leader and followers can communicate with each other.
- Gray failures can disrupt availability because there might be a false positive in failure detection or no failure detection
- For example, a replica that isn’t receiving heartbeats from a leader will try to elect a new leader. This can disrupt availability.
- [Solution] To solve the availability problem caused by gray failures, a follower that wants to trigger a failover sends a message to other replicas in the replication group asking if they can communicate with the leader. If replicas respond with a healthy leader message, the follower drops its attempt to trigger a leader election. This change in the failure detection algorithm used by DynamoDB significantly minimized the number of false positives in the system, and hence the number of spurious leader elections.
Measuring Availability
- DynamoDB is designed for 99.999(5-9s) percent availability for global tables and 99.99**(4-9s)** percent availability for regional tables.
- To ensure these goals are being met, DynamoDB continuously monitors availability at service and table levels. The tracked availability data is used to analyze customer perceived availability trends and trigger alarms if customers see errors above a certain threshold. These alarms are called customer-facing alarms (CFA) to report any availability-related problems and proactively mitigate the problem either automatically or through operator intervention.
- In addition to real time monitoring of availability, the system runs daily jobs that trigger aggregation to calculate aggregate availability metrics per customer.
- DynamoDB also measures and alarms on availability observed on the client-side. There are two sets of clients used to measure the user-perceived availability.
- Real application traffic allows us to reason about DynamoDB availability and latencies as seen by our customers and catch gray failures.
Deployments
- Unlike a traditional relational database, DynamoDB takes care of deployments without the need for maintenance windows and without impacting the performance and availability that customers experience.
- The rollback procedure is often missed in testing and can lead to customer impact. DynamoDB runs a suite of upgrade and downgrade tests at a component level before every deployment.
- [Problem] Deployments are not atomic in a distributed system. At any given time, there will be software running the old code on some nodes and new code on other parts of the fleet.
- New software might introduce a new type of message or change the protocol in a way that old software in the system doesn’t understand.
- [Solution] DynamoDB handles these kinds of changes with read-write deployments. Read-write deployment is completed as a multi-step process.
- The first step is to deploy the software to read the new message format or protocol. Once all the nodes can handle the new message, the software is updated to send new messages.
- Read-write deployments ensure that both types of messages can coexist in the system. Even in the case of rollbacks, the system can understand both old and new messages.
- [OneBox] Deployments are done on a small set of nodes before pushing them to the entire fleet of nodes. The strategy reduces the potential impact of faulty deployments.
- [AutoRollback AlarmWatcher/ApprovalWorkflow] DynamoDB sets alarm thresholds on availability metrics. If error rates or latency exceed the threshold values during deployments, the system triggers automatic rollbacks.
- **[Problem]**Software deployments to storage nodes trigger leader failovers that are designed to avoid any impact to availability.
Dependencies on External Services
- To ensure high availability, all the services that DynamoDB depends on in the request path should be more highly available than DynamoDB.
- Alternatively, DynamoDB should be able to continue to operate even when the services on which it depends are impaired.
- Examples of services DynamoDB depends on for the request path include AWS Identity and Access Management Services (IAM), and AWS Key Management Service (AWS KMS) for tables encrypted using customer keys. DynamoDB uses IAM and AWS KMS to authenticate every customer request.
- While these services are highly available, DynamoDB is designed to operate when these services are unavailable without sacrificing any of the security properties that these systems provide.
- In the case of IAM and AWS KMS, DynamoDB employs a statically stable design, where the overall system keeps working even when a dependency becomes impaired.
- Perhaps the system doesn’t see any updated information that its dependency was supposed to have delivered. However, everything before the dependency became impaired continues to work despite the impaired dependency.
- DynamoDB caches result from IAM and AWS KMS in the request routers that perform the authentication of every request. DynamoDB periodically refreshes the cached results asynchronously.
- If AWS IAM or KMS were to become unavailable, the routers will continue to use the cached results for a predetermined extended period.
- Caches improve response times by removing the need to do an off-box call, which is especially valuable when the system is under high load.
Metadata Availability
- One of the most important pieces of metadata the request routers needs is the mapping between a table’s primary keys and storage nodes.
- [Metadata Storage]At launch, DynamoDB stored the metadata in DynamoDB itself.
- [Routing Schema] This routing information consists of all the partitions for a table, the key range of each partition, and the storage nodes hosting the partition.
- [Router Metadata Caching] When a router received a request for a table it had not seen before, it downloaded the routing information for the entire table and cached it locally. Since the configuration information about partition replicas rarely changes, the cache hit rate was approximately 99.75 percent.
DynamoDB Limits
- **Per Partition Read and Write Capacity Units - **Ref
- 1 MB limit on the size of data returned by a single Query, Scan/GetItem Op.
- BatchGetItem operation can return up to 16MB of data - Ref
- Item Size Limit: Ref
- **Secondary Indexes - **Ref
- Transactions:
MicroBenchmarks
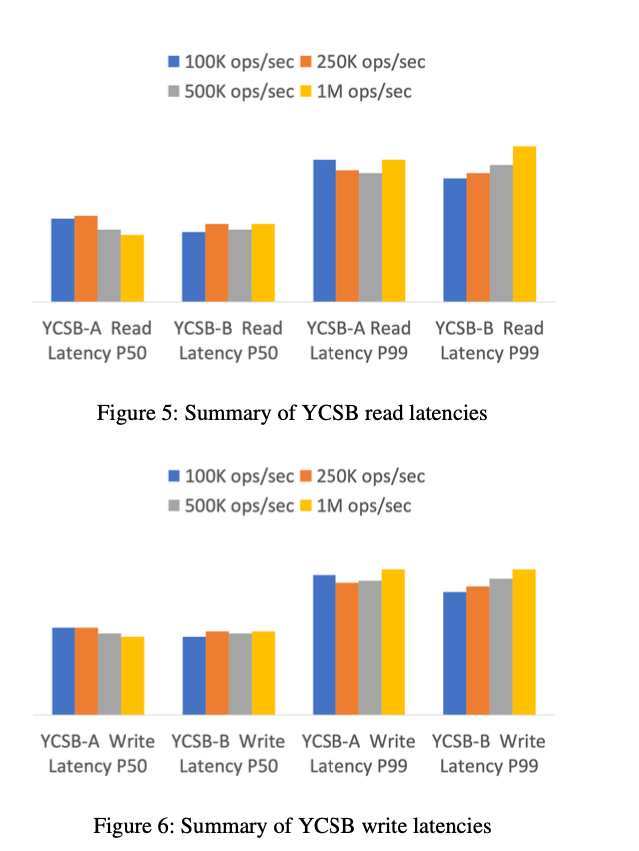
- To show that scale doesn’t affect the latencies observed by applications, we ran YCSB [8] workloads of types A (50 percent reads and 50 percent updates) and B (95 percent reads and 5 percent updates)
- Both benchmarks used a uniform key distribution and items of size 900 bytes.
- The workloads were scaled from 100 thousand total operations per second to 1 million total operations per second.
- The purpose of the graph is to show, even at different throughput, DynamoDB read latencies show very little variance and remain identical even as the throughput of the workload is increased.
Paper Link: https://www.usenix.org/conference/atc22/presentation/elhemali
Last updated: March 15, 2026
Questions or discussion? Email me