Paper: Google File System
Google File System / Distributed File System
Goal
Design a distributed file system to store huge files (terabyte and larger). The system should be scalable, reliable, and highly available.
- Developed by Google for its large data-intensive applications.
Background
- GFS was built for handling batch processing on large data sets and is designed for system-to-system interaction, not user-to-system interaction.
- Was designed with following goals in mind:
GFS Use Cases
- Built for distributed data-intensive applications like Gmail or Youtube.
- Google’s BigTable uses GFS to store log files and data files.
APIs
- GFS doesn’t provide a standard posix-like API. Instead user-level APIs are provided.
- Files organized hierarchically in directories and identified by their path names.
- Supports usual file system operations:
- Additional Special Operations
High Level Architecture
Agenda
- Chunks
- Chunk Handle
- Cluster
- Chunk Server
- Master
- Client A GFS cluster consists of a single master and multiple chunk servers and is accessed by multiple clients.
Chunk
- As files stored in GFS tend to be very large, GFS breaks files into multiple fixed-size chunks where each chunk is 64 megabytes in size.
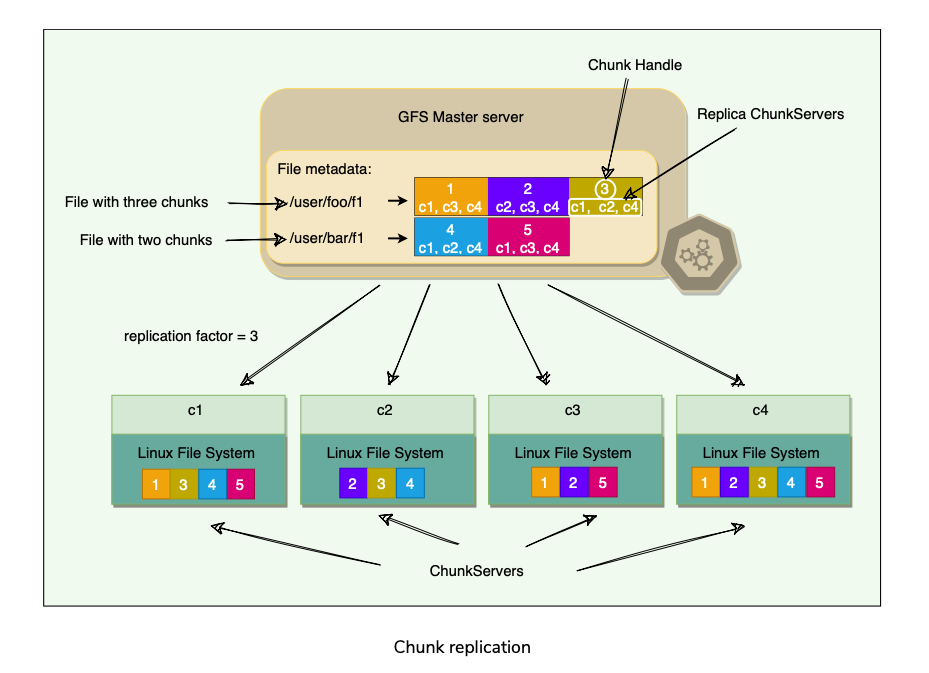
Chunk Handle
- Each chunk is identified by an Immutable and globally unique 64-bit ID number called chunk handle. Allows 2^64 unique chunks.
- Total allowed storage space = 2^64 * 64MB = 10^9 exabytes
- Files are split into Chunks, so the job of GFS is to provide a mapping from files to Chunks, and then to support standard operations on Files, mapping down operations to individual chunks.
Cluster
- GFS is organized into a network of computers(nodes) called a cluster. A GFS cluster contains 3 types of entities:
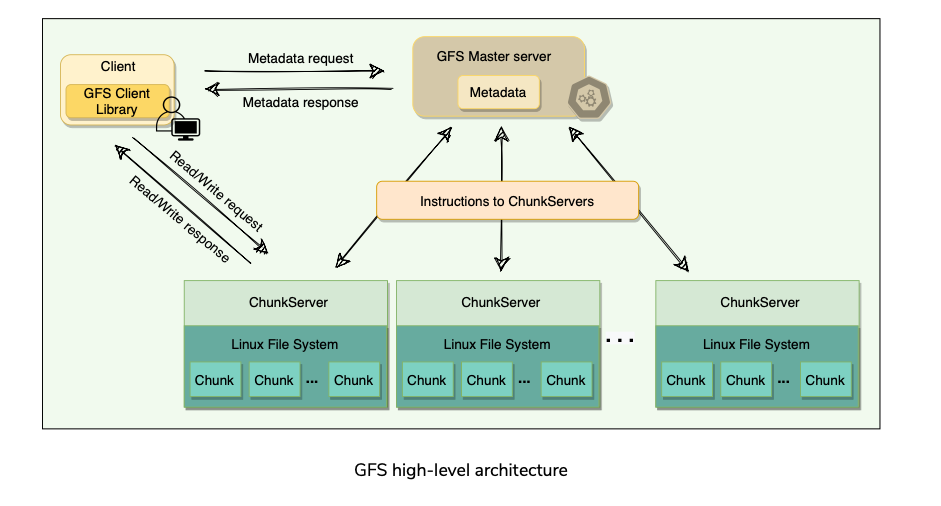
Chunk Server
- Nodes which stores chunks on local disks as linux files
- Read or write chunk data specified by chunk handle and byte-range.
- For reliability, each chunk is replicated to multiple chunk servers.
- By default, GFS stores three replicas, though different replication factors can be specified on a per-file basis.
Master
- Coordinator of GFS cluster. Responsible for keeping track of filesystem metadata.
- Metadata stored at master includes:
- Master also controls system-wide activities such as:
- Periodically communicates with each ChunkServer in HeartBeat messages to give it instructions and collect its state.
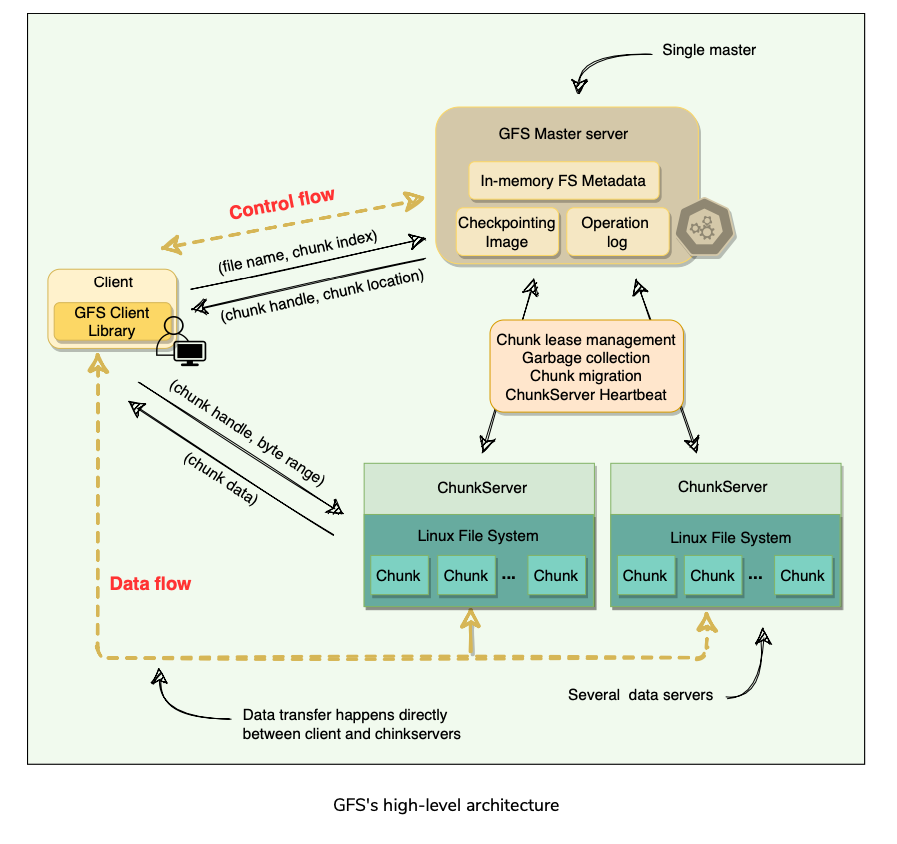
- For performance and fast random access, all metadata is stored in the master’s main memory, i.e. entire filesystem namespace as well as all the name-to-chunk mappings.
- For fault tolerance and to handle a master crash, all metadata changes(every operation to File System) are written to the disk onto an operation log(similar to Journal) which is replicated to remote machines.
- The benefit of having a single, centralized master is that it has a global view of the file system, and hence, it can make optimum management decisions, for example, related to chunk placement.
Client
- Application/Entity that makes read/write requests to GFS using GFS Client library.
- This library communicates with the master for all metadata-related operations like creating or deleting files, looking up files, etc.
- To read or write data, the client(library) interacts directly with the ChunkServers that hold the data.
- Neither the client nor the ChunkServer caches file data.
- ChunkServers rely on the buffer cache in Linux to maintain frequently accessed data in memory.
Single Master and Large Chunk Size
Agenda
- Single Master
- Chunk Size
Single Master
- Having a single master vastly simplifies GFS design and enables the master to make sophisticated chunk placement and replication decisions using global knowledge.
- GFS minimizes the master’s involvement in reads and writes, so that it does not become a bottleneck.
Chunk Size
- GFS has chosen 64 MB, which is much larger than typical filesystem block sizes (which are often around 4KB). One of the key design parameters.
- Advantages of large chunk size:
Lazy space Allocation
- Each chunk replica is stored as a plain Linux file on a ChunkServer. GFS does not allocate the whole 64MB of disk space when creating a chunk. Instead, as the client appends data, the ChunkServer, lazily extends the chunk
- One disadvantage of having a large chunk size is the handling of small files.
Metadata
Let’s explore how GFS manages file system metadata.
Agenda
Storing Metadata in memory
Chunk Location
Operation Log Master stores 3 types of metadata:
File and Chunk name spaces(Directory hierarchy).
Mapping from files to chunks.
Location of each chunk’s replica. 3 Aspects of how master stores this metadata:
Keeps all the metadata in memory.
File and Chunk namespaces and file-to-Chunk mapping are also persisted on Master’s local disk.
Chunk’s replica locations are not persisted on to local disk.
Storing Metadata in Memory
- Quick operations due to metadata being accessible in-memory.
- Efficient for the master to periodically scan through its entire state in the background. Periodic scanning is used for three functions:
- Capacity of the whole system(or How many chunks can the metadata store) is limited by how much memory the master has. Not a problem in practice.
- If the need to support a larger file system arises, cost of adding extra memory to master is a smaller price to pay for reliability, simplicity, performance, and flexibility by storing metadata in-memory.
Chunk Location
- The master does not keep a persistent record of which ChunkServers have a replica of a given chunk.
- By having the ChunkServer as the ultimate source of truth of each chunk’s location, GFS eliminates the problem of keeping the master and ChunkServers in sync
- It is not beneficial to maintain a consistent view of chunk locations on the master, because errors on a ChunkServer may cause chunks to vanish spontaneously (e.g., a disk may go bad and be disabled, or ChunkServer is renamed or failed, etc.)
Operation Log
- The master maintains an operation log that contains the namespace and file- to-chunk mappings and stores it on the local disk.
- Specifically, this log stores a historical persistent record of all the metadata changes and serves as a logical timeline that defines the order of concurrent operations.
- For fault tolerance and reliability, this operation log is synchronously replicated on multiple remote machines, and changes to the metadata are not made visible to clients until they have been persisted on all replicas.(Similar to the High Water Mark concept in Kafka).
- The master batches several log records together before flushing, thereby reducing the impact of flushing and replicating on overall system throughput.
- Upon restart, the master can restore its file-system state by replaying the operation log.
- This log must be kept small to minimize the startup time, and that is achieved by periodically checkpointing it.(What does this mean?)
Checkpointing
- Master’s state is periodically serialized to disk and then replicated, so that on recovery, a master may load the checkpoint into memory, replay any subsequent operations from the operation log, and be available very quickly.
- To further speed up the recovery and improve availability, GFS stores the checkpoint in a compact B-tree like format that can be directly mapped into memory and used for namespace lookup without extra parsing.
- The checkpoint process can take time, therefore, to avoid delaying incoming mutations, the master switches to a new log file and creates the new checkpoint in a separate thread.
Master Operations
Agenda
Namespace management and locking
Replica placement
Replica creation and re-replication
Replica rebalancing
Stale replica detection Master is responsible for:
Making replica placement decision
Creating new Chunks and assigning replicas
Making sure that the chunks are fully replicated as per replication factor
Balancing the load across chunk servers
Reclaimed unused storage.
Namespace management and locking
- The master acquires locks over a namespace region to ensure proper serialization and to allow multiple operations at the master.
- GFS does not have an i-node like tree structure for directories and files.
- Instead, it has a hash-map that maps a filename to its metadata, and reader-writer locks are applied on each node of the hash table for synchronization.
Replica placement
- To ensure maximum data availability and integrity, the master distributes replicas on different racks(“Rack Aware”), so that clients can still read or write in case of a rack failure.
- As the in and out bandwidth of a rack may be less than the sum of the bandwidths of individual machines, placing the data in various racks can help clients exploit reads from multiple racks.
- For ‘write’ operations, multiple racks are actually disadvantageous as data has to travel longer distances. It is an intentional tradeoff that GFS made.
- Data is lost when all replicas of a chunk are lost.
Replica creation and re-replication
- The goals of a master are to place replicas on servers with less-than-average disk utilization, and spread replicas across racks.
- Reduce the number of ‘recent’ creations on each ChunkServer (even though writes are cheap, they are followed by heavy write traffic) which might create additional load.
- Chunks need to be re-replicated as soon as the number of available replicas falls (due to data corruption on a server or a replica being unavailable) below the user-specified replication factor.
- Instead of re-replicating all of such chunks at once, the master prioritizes the client operations re-replication to prevent these cloning operations from becoming bottlenecks.What?
- Restrictions are placed on the bandwidth of each server for re-replication so that client requests are not compromised.
- How are chunks prioritized for re-replication?
Replica rebalancing
- Master rebalances replicas regularly to achieve load balancing and better disk space usage.
- Any new ChunkServer added to the cluster is filled up gradually by the master rather than flooding it with a heavy traffic of write operations.
Stale replica detection
- Chunk replicas may become stale if a ChunkServer fails and misses mutations to the chunk while it is down
- For each chunk, the master maintains a chunk Version Number to distinguish between up-to-date and stale replicas.
- The master increments the chunk version every time it grants a lease and informs all up-to-date replicas.
- The master and these replicas all record the new version number in their persistent state.
- Master removes stale replicas during regular garbage collection.
- Stale replicas are not given to clients when they ask the master for a chunk location, and they are not involved in mutations either.
- However, because a client caches a chunk’s location, it may read from a stale replica before the data is resynced.
Anatomy of a Read Operation
Let’s learn how GFS handles a read operation. A typical interaction with GFS Cluster goes like this:
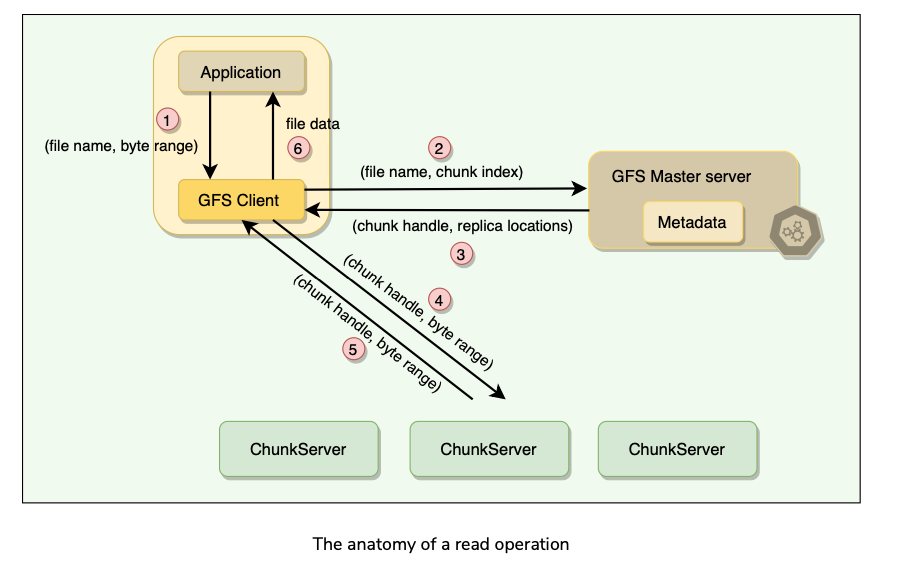
- Client translates the filename and byte offset specified by the application into a chunk index within the file.
- Client sends RPC request with File Name and Chunk Index to the master.
- Master replies with Chunk Handle and replica locations(holding chunk).
- Client caches this metadata using FileName and ChunkIndex as the key.
- Client sends request to one of the closest replicas specifying a chunk handle and a byte range within that chunk.
- Replica chunk server replies with requested data.
- Master is involved only at the start and is then completely out of loop, implementing a separation of control and data flows.
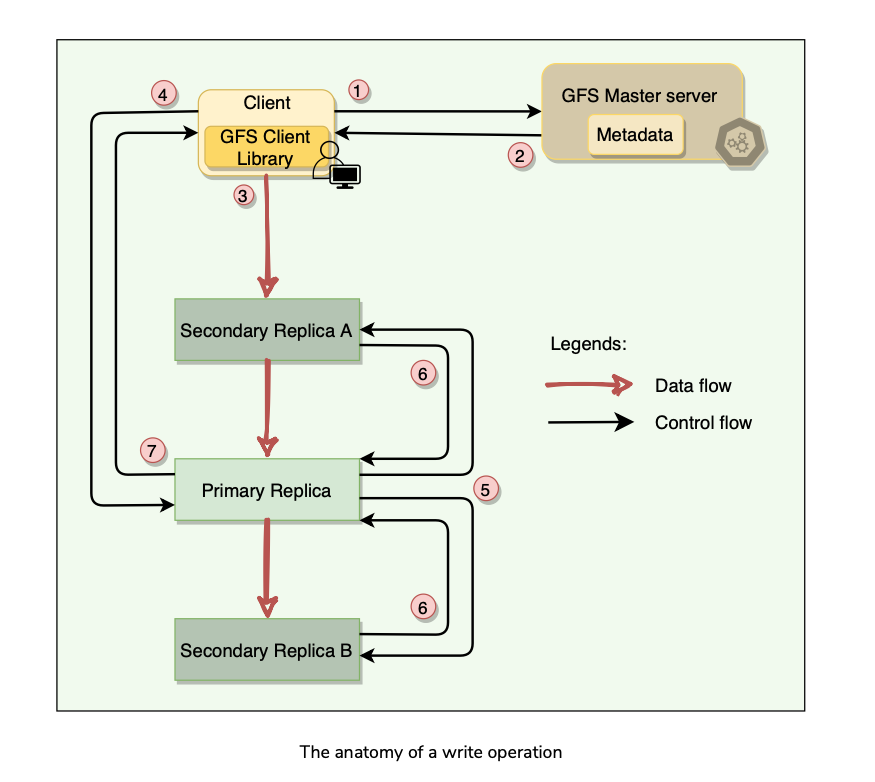
Anatomy of Write Operation
What is a chunk lease?
- To safeguard against concurrent writes at two different replicas of a chunk, GFS makes use of chunk lease.
- When a mutation (i.e., a write, append or delete operation) is requested for a chunk, the master finds the ChunkServers which hold that chunk and grants a chunk lease (for 60 seconds) to one of them.
- The server with the lease is called the primary and is responsible for providing a serial order for all the currently pending concurrent mutations to that chunk.
- There is only one lease per chunk at any time, so that if two write requests go to the master, both see the same lease denoting the same primary.
- A global ordering is provided by the ordering of the chunk leases combined with the order determined by that primary.
- The primary can request lease extensions if needed
- When the master grants the lease, it increments the chunk version number and informs all replicas containing that chunk of the new version number.
- Failure modes??
Data Writing?
Writing of data is split into two phases:
Sending
Writing Stepwise breakdown of data transfer:
Client asks master which chunk server holds the current lease of chunk and locations of other replicas.
Master replies with the identity and location of primary and secondary replicas.
Client pushes data to the closest replica.
Once all replicas have acknowledged receiving the data, the client sends the write request to the primary.
The primary assigns consecutive serial numbers to all the mutations it receives, providing serialization. It applies mutations in serial number order.
Primary forwards the write request to all secondary replicas. They apply mutations in the same serial number order.
Secondary replicas reply to primary indicating they have completed operation.
Primary replies to the client with success or error messages.
The key point to note is that the data flow is different from the control flow.
Chunk version numbers are used to detect if any replica has stale data which has not been updated because that ChunkServer was down during some update.
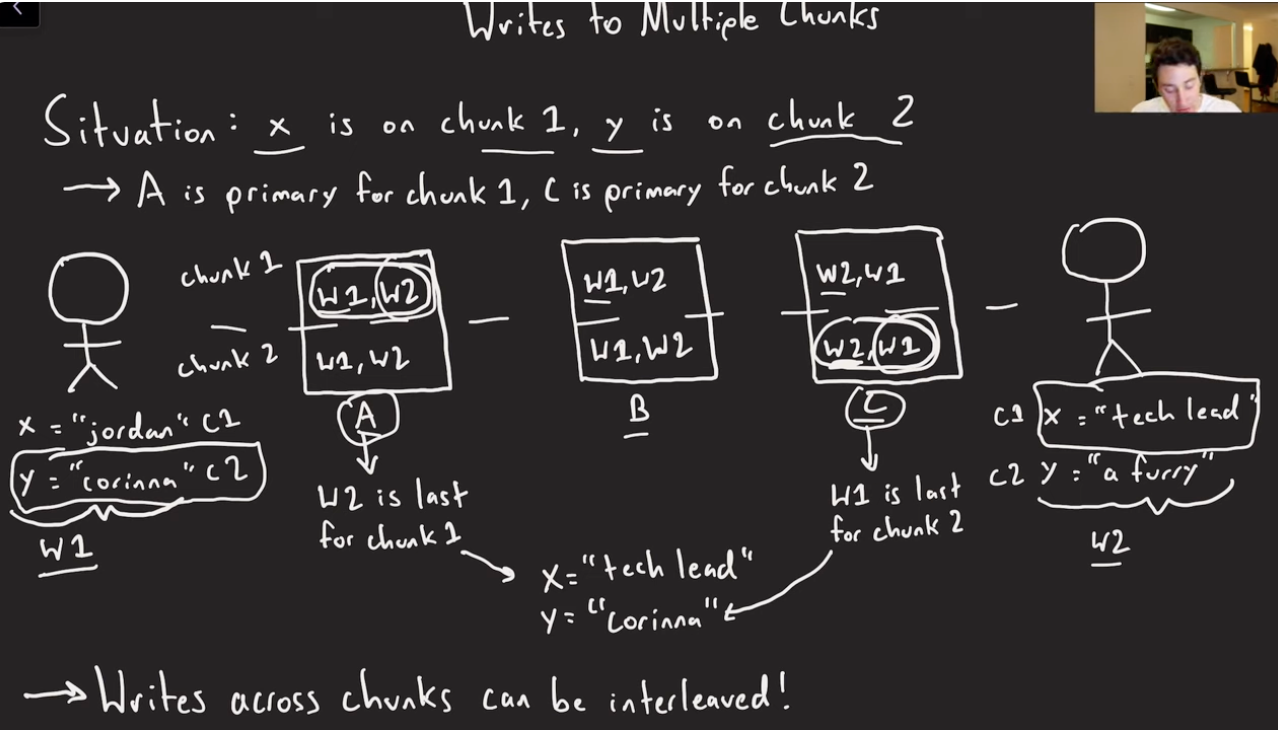
Another edge case with write operation is that, if we have two concurrent write operations spanning multiple chunks, and the chunks have two different primary chunk servers, which decide on the single order, it could happen that you may have interleaved concurrent writes in those cases. See example below. From the Jordan video here at time 22:30 onwards. Only solution for that is Distributed Locking Service(Distributed Consensus), which is going to be an expensive operation.
Anatomy of Append operation?
- Record append operation is optimized in a unique way that distinguishes GFS from other distributed file systems.
- In a normal write, the client specifies the offset at which data is to be written. Concurrent writes to the same region can experience race conditions, and the region may end up containing data fragments from multiple clients.
- In a record append, however, the client specifies only the data(up to 1/4th of a chunk size ~~ 16 MB). GFS appends it to the file at least once atomically (i.e., as one continuous sequence of bytes) at an offset of GFS’s choosing and returns that offset to the client.
- Record Append is a kind of mutation that changes the contents of the metadata of a chunk.
- [Data Transfer to Replicas] When an application tries to append data on a chunk by sending a request to the client, the client pushes the data to all replicas of the last chunk of the file just like the write operation.
- [Command to serialize the write] When the client forwards the request to the master, the primary checks whether appending the record to the existing chunk will increase the chunk’s size more than its limit (maximum size of a chunk is 64MB).
- [Pads the existing Chunk] If this happens, it pads the chunk to the maximum limit, commands the secondary to do the same, and requests the clients to try to append to the next chunk.
- [Append to the primary replica’s chunk and notify secondary] If the record fits within the maximum size, the primary appends the data to its replica, tells the secondary to write the data at the exact offset where it has, and finally replies success to the client.
- [Failure Mode] If an append operation fails at any replica, the client retries the operation.
Implications for Writes(Jordan Video:27:40)
- Prefer appends to writes.
- No Interleaving.
- Readers need to be able to handle padding and/or duplicates(can happen due to failed retries or partial failures on some of the replicas).
- If making multi-chunk writes, writers should take checkpoints as each of those individual write chunks goes through.
GFS consistency model and Snapshotting
GFS Consistency model
- GFS has a relaxed consistency model.(Don’t know what that means)
- Metadata operations (e.g., file creation) are atomic.
- Namespace locking guarantees atomicity and correctness.
- Master’s operation log defines a global total order of these operations.
- In data mutations, there is an important distinction between write and append operations.
- Write operations specify an offset at which mutations should occur, whereas appends are always applied at the end of the file.
- This means that for the write operation, the offset in the chunk is predetermined, whereas for append , the system decides.
- Concurrent writes to the same location are not serializable and may result in corrupted regions of the file.
- With append operations, GFS guarantees the append will happen at-least-once and atomically (that is, as a contiguous sequence of bytes).
- The system does not guarantee that all copies of the chunk will be identical (some may have duplicate data).
Snapshotting
- A snapshot is a copy of some subtree of the global namespace as it exists at a given point in time.
- GFS clients use snapshotting to efficiently branch two versions of the same data.
- Snapshots in GFS are initially zero-copy.
- When the master receives a snapshot request, it first revokes any outstanding leases on the chunks in the files to snapshot.
- It waits for leases to be revoked or expired and logs the snapshot operation to the operation log.
- The snapshot is then made by duplicating the metadata for the source directory tree.
- When a client makes a request to write to one of these chunks, the master detects that it is a copy-on-write chunk by examining its reference count (which will be more than one).
- At this point, the master asks each ChunkServer holding the replica to make a copy of the chunk and store it locally.
- Once the copy is complete, the master issues a lease for the new copy, and the write proceeds.
Fault Tolerance, High Availability, and Data Integrity
Agenda
- Fault Tolerance
- High Availability through chunk replication
- Data Integrity through checksum.
Fault Tolerance
To make the system fault tolerant, and available, GFS uses two strategies:
Fast recovery in case of component failures.
Replication for high availability. Lets see how GFS recovers from Master or Replica Failure:
On Master Failure
On Primary Replica Failure
On Secondary Replica Failure
Stale replicas might be exposed to clients. It depends on the application programmer to deal with these stale reads.
High Availability through chunk replication
- Each chunk is replicated on multiple ChunkServers on different racks.
- Users can specify different replication levels(Default: 3) for different parts of the file namespace.
- The master clones the existing replicas to keep each chunk fully replicated as ChunkServers go offline or when the master detects corrupted replicas through checksum verification.
- A chunk is lost irreversibly only if all its replicas are lost before GFS can react. Even in this case, the data becomes unavailable, not corrupted, which means applications receive clear errors rather than corrupt data.
Data Integrity through checksum
Checksumming is used by each ChunkServer to detect the corruption of stored data.
The chunk is broken down into 64 KB blocks.
Each 64 KB block has a corresponding 32-bit checksum.
Like other metadata, checksums are kept in memory and stored persistently with logging, separate from user data.
For Reads: the ChunkServer verifies the checksum of data blocks that overlap the read range before returning any data to the requester, whether a client or another ChunkServer. ChunkServers will not propagate corruptions to other machines.
For Writes:
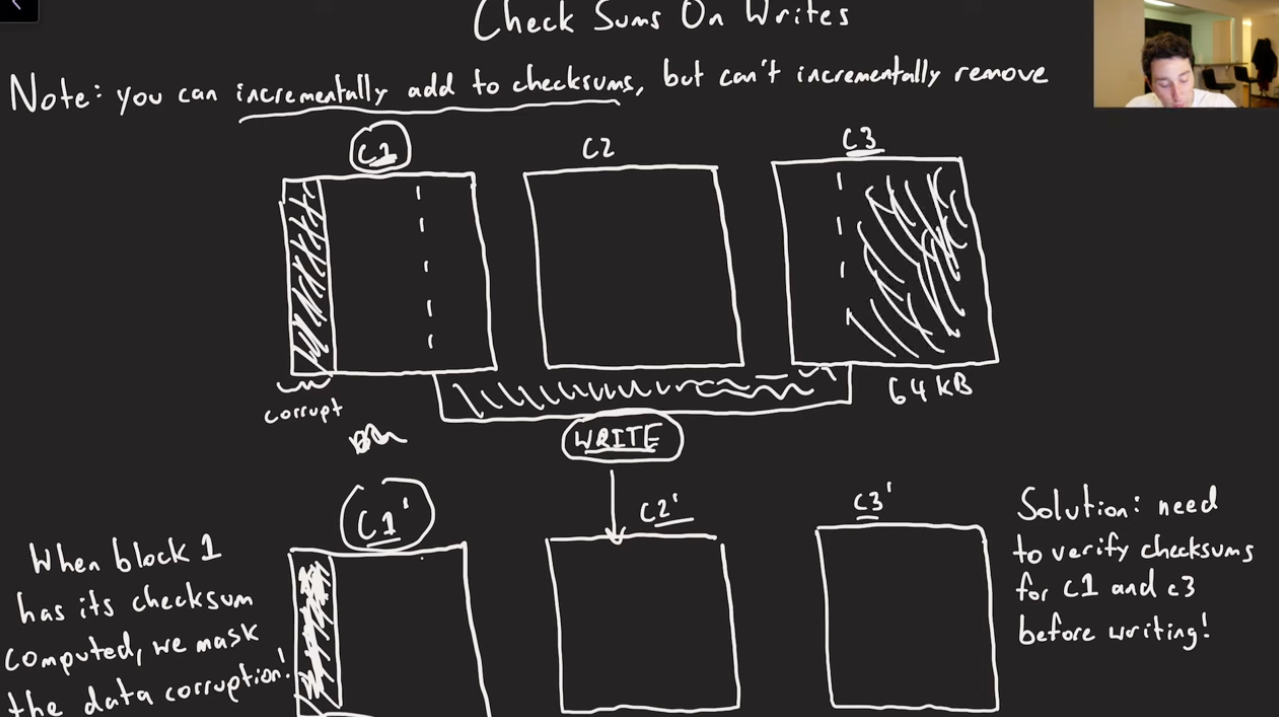
For Appends:
During idle periods, ChunkServers can scan and verify the contents of inactive chunks (prevents an inactive but corrupted chunk replica from fooling the master into thinking that it has enough valid replicas of a chunk).
Checksumming has little effect on read performance for the following reasons:
Garbage Collection
How does GFS implement Garbage Collection?
Agenda
- Garbage collection through lazy deletion
- Advantages of lazy deletion
- Disadvantages of lazy deletion
Garbage collection through lazy deletion
- When a file is deleted, GFS does not immediately reclaim the physical space used by that file. Instead, it follows a lazy garbage collection strategy.
- When the client issues a delete file operation, GFS does two things:
- The file can still be read under the new, special name and can also be undeleted by renaming it back to normal.
- To reclaim the physical storage, the master, while performing regular scans of the file system, removes any such hidden files if they have existed for more than three days (this interval is configurable) and also deletes its in-memory metadata.
- This lazy deletion scheme provides a window of opportunity to a user who deleted a file by mistake to recover the file.
- The master, while performing regular scans of the chunk namespace, deletes the metadata of all chunks that are not part of any file.
- Also, during the exchange of regular HeartBeat messages with the master, each ChunkServer reports a subset of the chunks it has, and the master replies with a list of chunks from that subset that are no longer present in the master’s database; such chunks are then deleted from the ChunkServer.
Advantages of lazy deletion
- Simple and reliable: If the chunk deletion message is lost, the master does not have to retry. The ChunkServer can perform the garbage collection with the subsequent heartbeat messages.
- GFS merges storage reclamation into regular background activities of the master, such as the regular scans of the filesystem or the exchange of HeartBeat messages. Thus, it is done in batches, and the cost is amortized.
- Garbage collection takes place when the master is relatively free.
- Lazy deletion provides safety against accidental, irreversible deletions.
Disadvantages of lazy deletion
- As we know, after deletion, storage space does not become available immediately. Applications that frequently create and delete files may not be able to reuse the storage right away. To overcome this, GFS provides following options:
Criticism on GFS
Problems associated with single master
- Google has started to see the following problems with the centralized master scheme:
Problems associated with large chunk size
- Large chunk size (64MB) in GFS has its disadvantages while reading. Since a small file will have one or a few chunks, the ChunkServers storing those chunks can become hotspots if a lot of clients are accessing the same file.
- As a workaround for this problem, GFS stores extra copies of small files for distributing the load to multiple ChunkServers. Furthermore, GFS adds a random delay in the start times of the applications accessing such files.
Summary
- Scalable distributed file storage system for large data-intensive applications.
- Uses commodity hardware to reduce infrastructure costs.
- Was designed with Fault Tolerance in mind(Software/hardware faults).
- Reading workload is large streaming reads and small random reads.
- Writing workload is many large sequential writes that appends data to files.
- Provides APIs for file operations like create, delete, open, close, read, write, snapshot and record append operations. Record append allows multiple clients to concurrently append data to the same file while guaranteeing atomicity.
- GFS cluster is single master, multiple chunk servers & access by Multiple clients.
- Files are broken into 64 MB chunks, identified by Immutable and Globally unique 64-bit Chunk Handle(assigned by master during chunk creation).
- Chunk servers store chunks on local disks as Linux files. For Reliability, each chunk is replicated to multiple chunk servers.
- Master is Coordinator for GFS cluster. Responsible for keeping track of all the filesystem metadata. Namespace, authorization, files-chunk mapping, chunk location.
- Master keeps all metadata in memory for faster operation. For Fault tolerance, and to handle master crash, all metadata changes are written onto disk into Operation Log which is replicated to other machines.
- Master doesn’t have a persistent record(only in-memory) of which chunk servers have replicas for a given chunk. Master asks each chunk server what chunks it holds at master startup, or whenever the chunk server joins the cluster.
- For Quick recovery(Master failure), master’s state is periodically serialized to disk(Checkpointed) along with Operation log and is replicated. On recovery, master loads the checkpoint, and replays subsequent operations from Operation Log.
- Master communicates with each chunk server via HeartBeat to collect state.
- Applications use GFS Client code, which implements filesystem API, and communicates with the cluster. Clients interact with master for metadata(Control Flow), but all data transfer happens directly(Data Flow) between client and Chunk servers.
- Data Integrity: Each Chunk server uses Checksumming to detect corruption of stored data.
- Garbage Collection: Lazy Deletion.
- Consistency:Master guarantees data consistency by ensuring order of mutations on all replicas and using chunk version numbers. If a replica has an incorrect version, it is garbage collected.
- GFS guarantees at-least-once writes. It is the responsibility of readers to deal with duplicate chunks. This is achieved by having Checksums and serial numbers in the chunks, which help readers to filter and discard duplicate data.
- Cache: Neither the client or chunk servers cache data. However, Clients do cache metadata.
System Design Patterns
- Write-Ahead-Log - Operation Log
- HeartBeat - B/w Master and Chunk servers.
- CheckSum - Data Integrity
- Copy-On-Write Snapshotting.
- Lazy Garbage collection.
References
- GFS Paper
- BigTable Paper
- GFS Evolution on Fast-Forward
- Jordan Video would give a quick summary of the above.
Paper Link: https://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf
Last updated: March 15, 2026
Questions or discussion? Email me