Paper: Hadoop Distributed File System
Hadoop Distributed File System
Goal
- Design a distributed system that can store huge files (terabyte and larger). The system should be scalable, reliable, and highly available.
What is Hadoop Distributed File System
- HDFS is a distributed file system and was built to store unstructured data. It is designed to store huge files reliably and stream those files at high bandwidth to user applications.
- HDFS is a variant and a simplified version of the Google File System (GFS). A lot of HDFS architectural decisions are inspired by GFS design. HDFS is built around the idea that the most efficient data processing pattern is a write-once, read-many-times pattern.
Background
- Apache Hadoop is a software framework that provides a distributed file storage system(HDFS) and distributed computing for analyzing and transforming very large data sets using the MapReduce programming model.
- HDFS is the default file storage system in Hadoop. It is designed to be a distributed, scalable, fault-tolerant file system that primarily caters to the needs of the MapReduce paradigm.
- Both HDFS and GFS were built to store very large files and scale to store petabytes of storage.
- Both were built for handling batch processing on huge data sets and were designed for data-intensive applications and not for end- users.
- Like GFS, HDFS is also not POSIX-compliant and is not a mountable file system on its own. It is typically accessed via HDFS clients or by using application programming interface (API) calls from the Hadoop libraries.
- Given HDFS design, following applications are not a good fit for HDFS,
API
- Provides user-level APIs(and not standard POSIX-like APIs).
- Files are organized hierarchically in directories and identified by their pathnames.
- Supports the usual file system operations on files and directories. Create, Delete, Rename, Move, and Symbolic Links(unlike GFS) etc.
- All read and write operations are done in an append-only fashion.
High Level Architecture
HDFS Architecture
Files are broken into 128 MB fixed-size blocks (configurable on a per-file basis).
File has two parts: the actual file data and the metadata.
Metadata
HDFS cluster primarily consists of a NameNode(Master:GFS) that manages the file system metadata and DataNodes(Chunk Server:GFS) that store the actual data.
All blocks of a file are of the same size except the last one.
HDFS uses large block sizes because it is designed to store extremely large files to enable MapReduce jobs to process them efficiently.
Each block is identified by a unique 64-bit ID called BlockID(Similar to Chunk in GFS). All read/write operations in HDFS operate at the block level.
DataNodes store each block in a separate file on the local file system and provide read/write access.
When a DataNode starts up, it scans through its local file system and sends the list of hosted data blocks (called BlockReport) to the NameNode.(Similar to how Master gets state information in GFS from Chunk Servers).
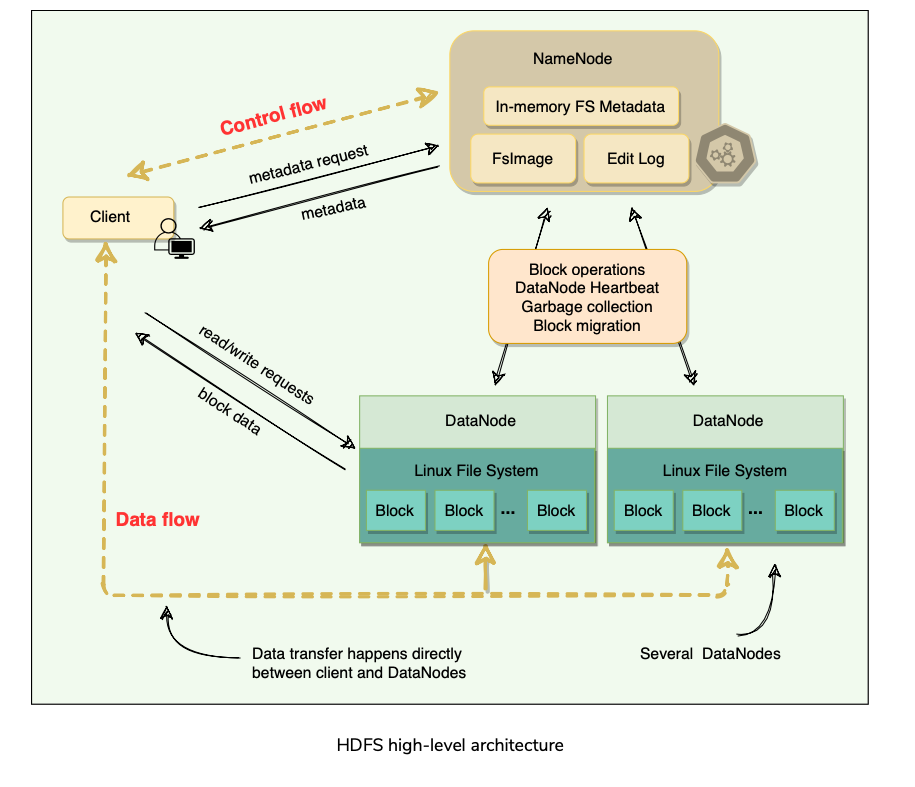
The NameNode maintains two on-disk data structures to store the file system’s state: an FsImage file(Oplog Checkpoint:GFS) and an EditLog(Operation Log: GFS).
FsImage is a checkpoint of the file system metadata at some point in time, while the EditLog is a log of all of the file system metadata transactions since the image file was last created. These two files help NameNode to recover from failure.
User applications interact with HDFS through its client. HDFS Client interacts with NameNode for metadata, but all data transfers happen directly between the client and DataNodes.
To achieve high-availability, HDFS creates multiple copies of the data and distributes them on nodes throughout the cluster.
Comparison b/w GFS and HDFS
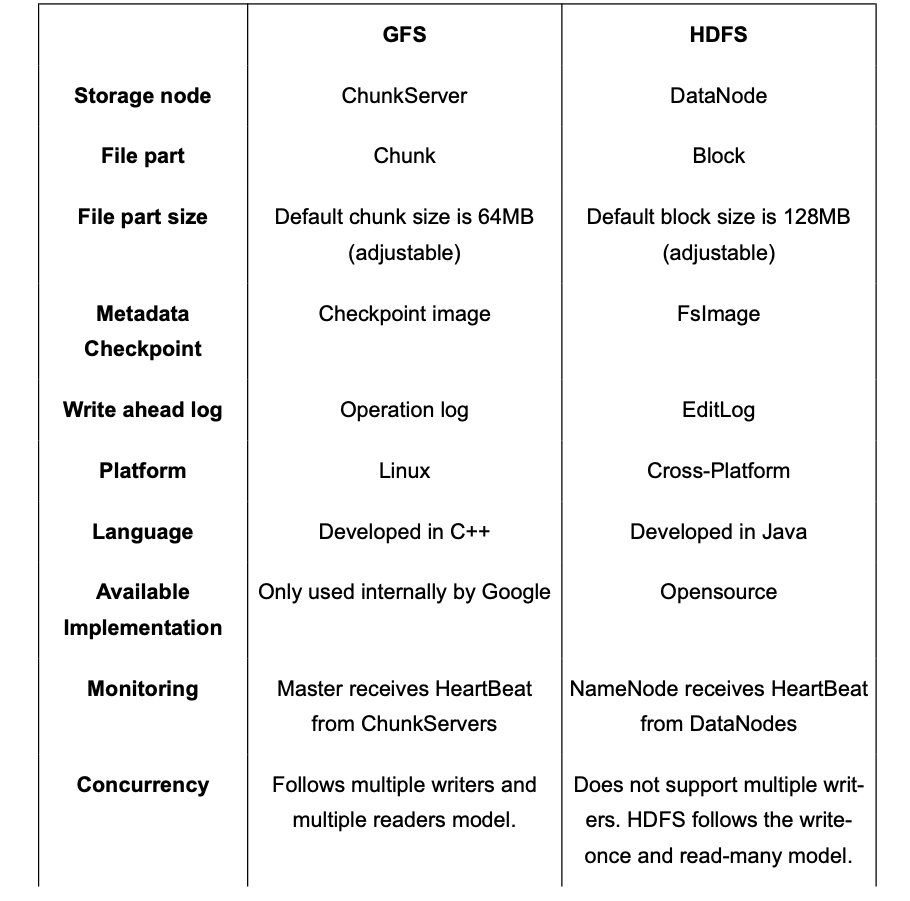
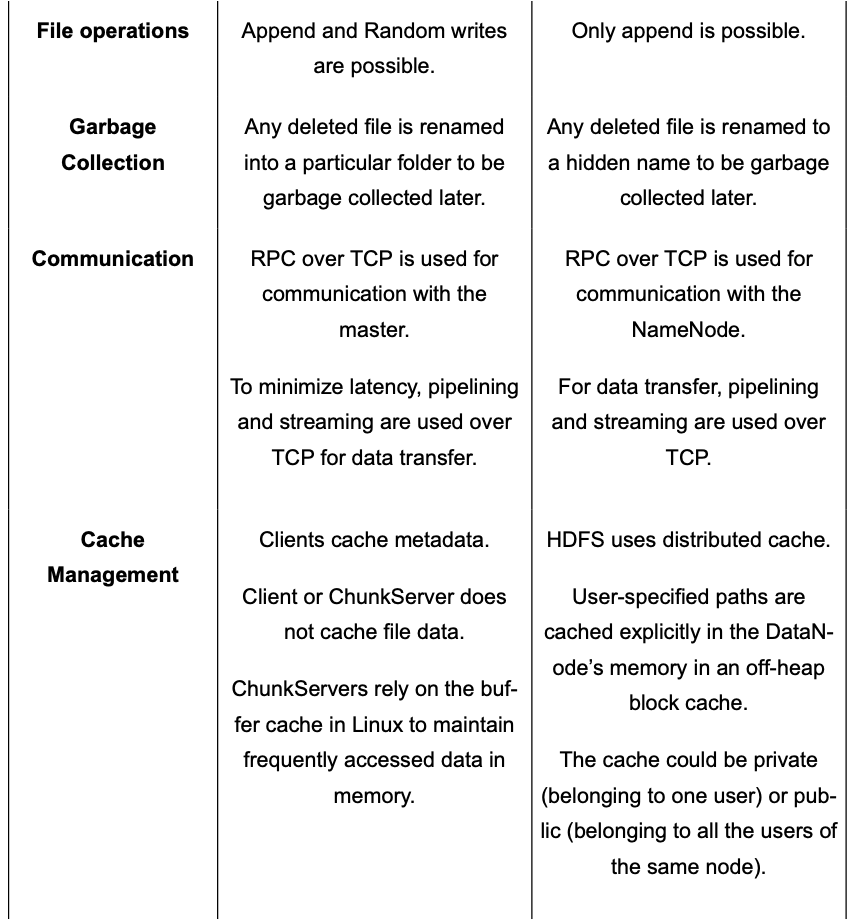
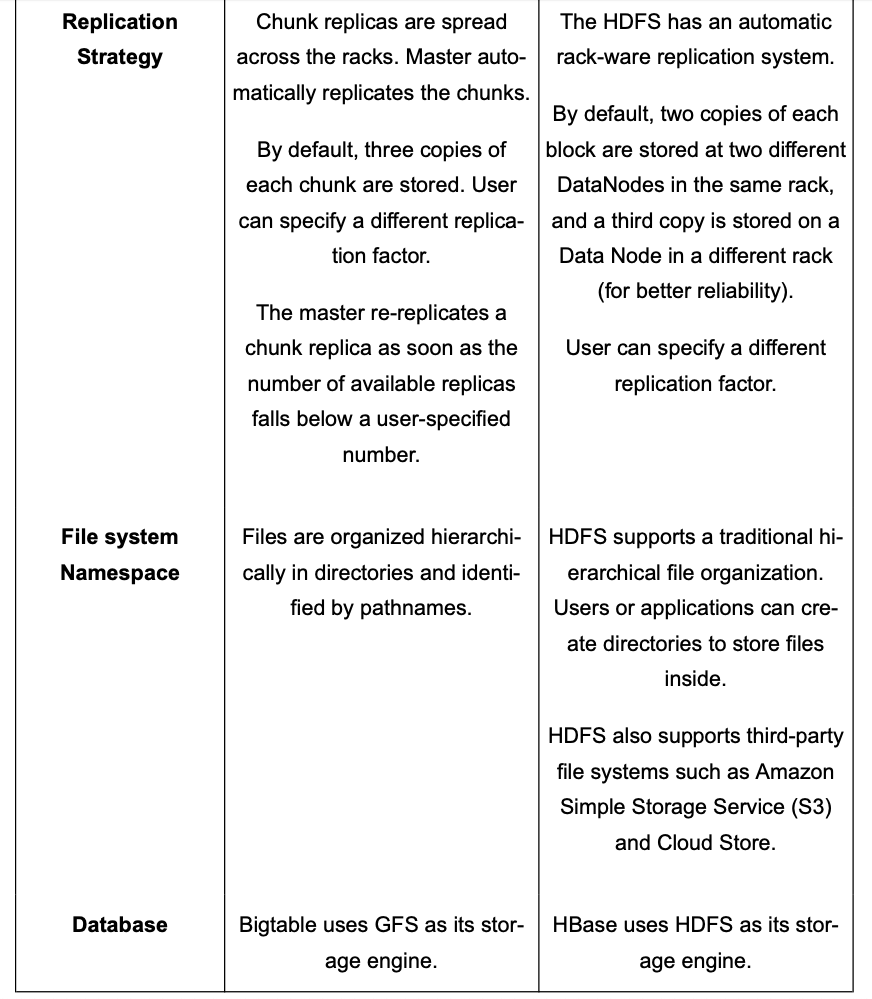
Deep Dive
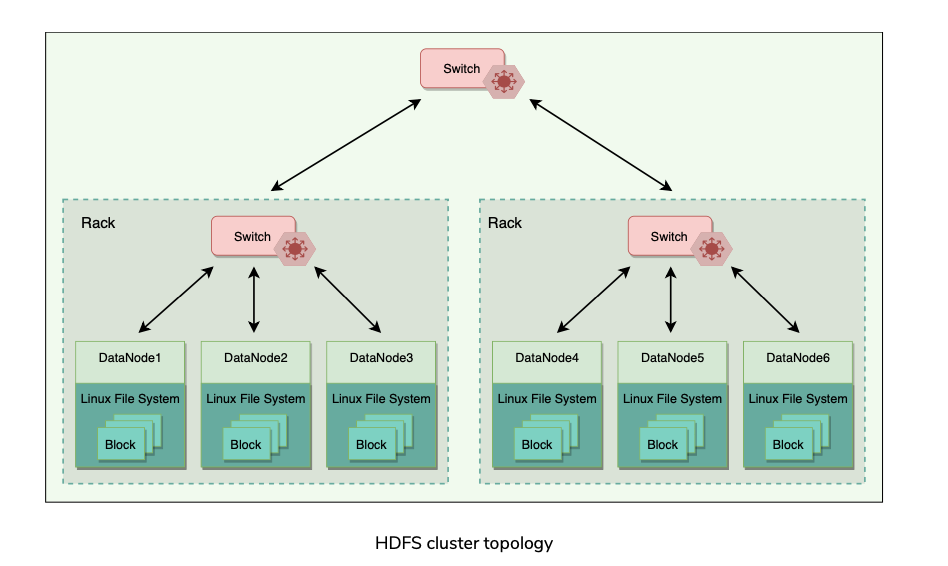
Cluster Topology
- Hadoop clusters typically have about 30 to 40 servers per rack.
- Each rack has a dedicated gigabit switch that connects all of its servers and an uplink to a core switch or router, whose bandwidth is shared by many racks in the data center.
- When HDFS is deployed on a cluster, each of its servers is configured and mapped to a particular rack. The network distance between servers is measured in hops, where one hop corresponds to one link in the topology.
- Hadoop assumes a tree-style topology, and the distance between two servers is the sum of their distances to their closest common ancestor.
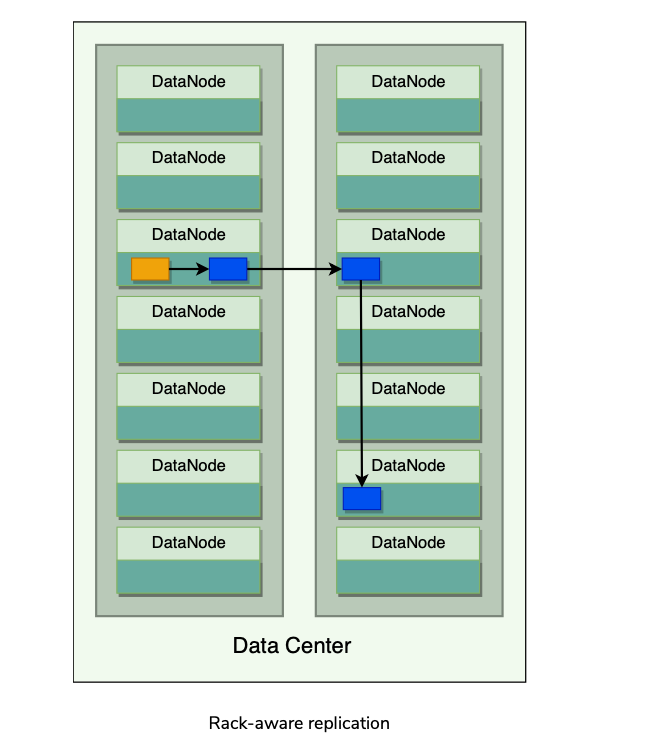
Rack aware replication
- HDFS employs a rack-aware replica placement policy to improve data reliability, availability, and network bandwidth utilization.
- The idea behind HDFS’s replica placement is to be able to tolerate node and rack failures.
- If the replication factor is three, HDFS attempts to place the
- This rack-aware replication scheme slows the write operation as the data needs to be replicated onto different racks, tradeoff between reliability and performance.
Synchronization Semantics
- Early versions of HDFS followed strict immutable semantics. Once a file was written, it could never again be re-opened for writes; files could still be deleted.
- Current versions of HDFS support append.
- This design choice in HDFS was because most MapReduce workloads follow the write once and read many data-access patterns.
- MapReduce is a restricted computational model with predefined stages. The reducers in MapReduce write independent files to HDFS as output. HDFS focuses on fast read access for multiple clients at a time.
HDFS Consistency Model
- HDFS follows a strong consistency model.
- To ensure strong consistency, a write is declared successful only when all replicas have been written successfully.
- HDFS does not allow multiple concurrent writers to write to an HDFS file, so implementing strong consistency becomes relatively easy.
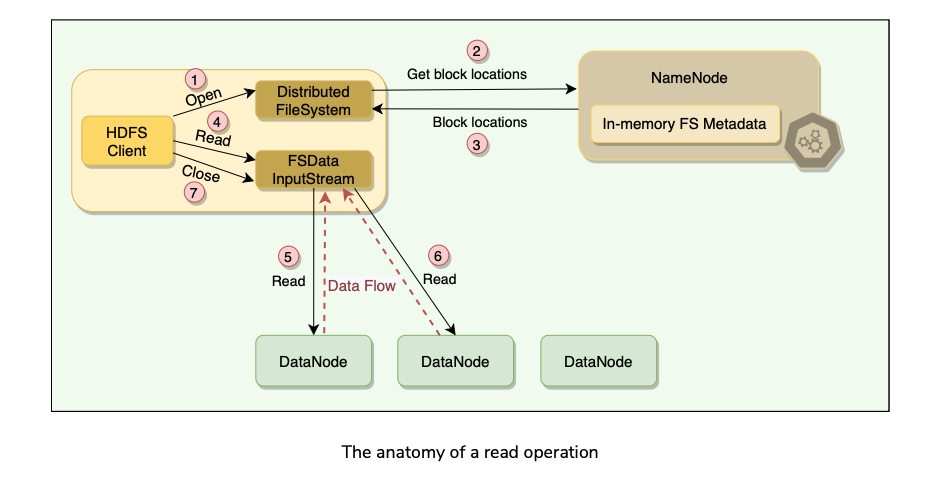
Anatomy of a Read Operation
HDFS Read Process
- (1) When a file is opened for reading, the HDFS client initiates a read request, by calling the open() method of the Distributed FileSystem object. The client specifies the file name, start offset, and the read range length**.**
- (2) The Distributed FileSystem object calculates what blocks need to be read based on the given offset and range length, and requests the locations of the blocks from the NameNode.
- (3) NameNode has metadata for all blocks’ locations. It provides the client a list of blocks and the locations of each block replica. As the blocks are replicated, NameNode finds the closest replica to the client when providing a particular block’s location. The closest locality of each block is determined as follows:
- (4) After getting the block locations, the client calls the read() method of FSData InputStream,which takes care of all the interactions with the DataNodes.
- (5) Once the client invokes the read() method, the input stream object establishes a connection with the closest DataNode with the first block of the file.
- (5b) The data is read in the form of streams and passed to the requesting application. Hence, the block does not have to be transferred in its entirety before the client application starts processing it.
- (6) Once the FSData* *InputStream receives all data of a block, it closes the connection and moves on to connect the DataNode for the next block. It repeats this process until it finishes reading all the required blocks of the file.
- (7) Once the client finishes reading all the required blocks, it calls the close() method of the input stream object.
Short Circuit Read
- If the data and the client are on the same machine, HDFS can directly read the file bypassing the DataNode. This scheme is called short circuit read and is quite efficient as it reduces overhead and other processing resources.
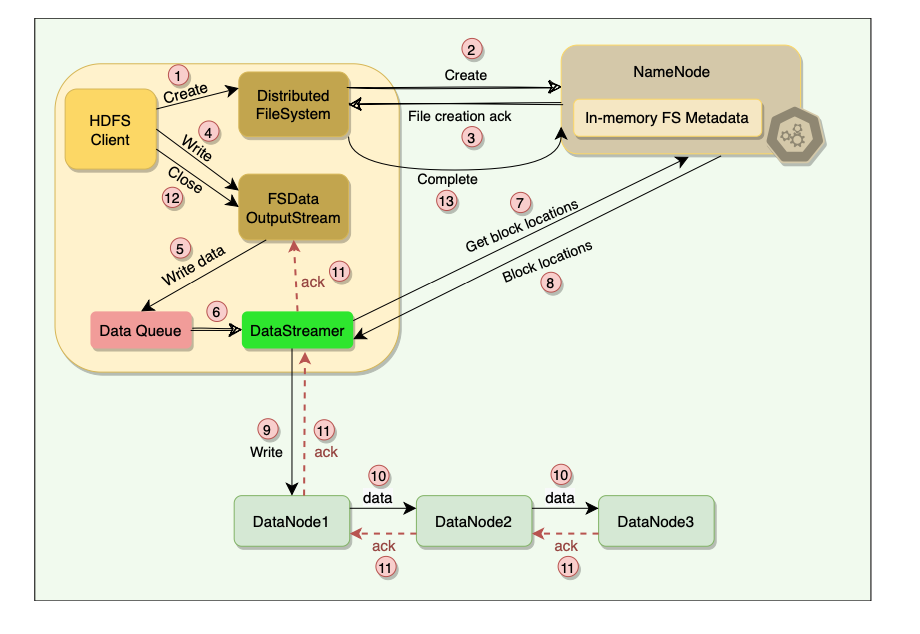
Anatomy of a Write Process
- HDFS client initiates a write request by calling the create() method of the Distributed FileSystem object.
- Distributed FileSystem object sends a file creation request to the NameNode.
- NameNode verifies that the file does not already exist and that the client has permission to create the file. If both these conditions are verified, the NameNode creates a new file record and sends an acknowledgment.
- Client proceeds to write the file using FSData OutputStream.
- FSData OutputStream writes data to a local queue called ‘Data Queue.’ The data is kept in the queue until a complete block of data is accumulated.
- Once the queue has a complete block, another component called DataStreamer is notified to manage data transfer to the DataNode.
- DataStreamer first asks the NameNode to allocate a new block on DataNodes, thereby picking desirable DataNodes to be used for replication.
- The NameNode provides a list of blocks and the locations of each block replica.
- Upon receiving the block locations from the NameNode, the DataStreamer starts transferring the blocks from the internal queue to the nearest DataNode.
- Each block is written to the first DataNode, which then pipelines the block to other DataNodes in order to write replicas of the block.
- Once the DataStreamer finishes writing all blocks, it waits for acknowledgments from all the DataNodes.
- Once all acknowledgments are received, the client calls the close() method of the OutputStream.
- Finally, the Distributed FileSystem contacts the NameNode to notify that the file write operation is complete. At this point, the NameNode commits the file creation operation, which makes the file available to be read.
Data Integrity(Block Scanner) & Caching
Data Integrity
- Data Integrity refers to ensuring the correctness of the data.
- When a client retrieves a block from a DataNode, the data may arrive corrupted. This corruption can occur because of faults in the storage device, network, or the software itself.
- HDFS client uses checksum to verify the file contents.
- When a client stores a file in HDFS, it computes a checksum of each block of the file and stores these checksums in a separate hidden file in the same HDFS namespace.
- When a client retrieves file contents, it verifies that the data it received from each DataNode matches the checksum stored in the associated checksum file.
- If not, then the client can opt to retrieve that block from another replica.
Block Scanner
- A block scanner process periodically runs on each DataNode to scan blocks stored on that DataNode and verify that the stored checksums match the block data.
- Additionally, when a client reads a complete block and checksum verification succeeds, it informs the DataNode. The DataNode treats it as a verification of the replica.
- Whenever a client or a block scanner detects a corrupt block, it notifies the NameNode.
- The NameNode marks the replica as corrupt and initiates the process to create a new good replica of the block.
Caching
- Normally, blocks are read from the disk, but for frequently accessed files, blocks may be explicitly cached in the DataNode’s memory, in an off-heap block cache.
- HDFS offers a Centralized Cache Management scheme to allow its clients to specify to the NameNode file paths which need to be cached.
- NameNode communicates with the DataNodes that have the desired blocks on disk and instructs them to cache the blocks in off-heap caches.
- Advantages of Centralized Cache management in HDFS:
Fault Tolerance
Agenda
- How does HDFS handle DataNode failures?
- What happens when the NameNode fails?
How does HDFS handle DataNode failures?
Replication
- As the blocks are replicated to multiple(Default 3) datanodes’ replicas, if one DataNode becomes inaccessible, its data can be read from other replicas.
HeartBeat
- The NameNode keeps track of DataNodes through a heartbeat mechanism. Each DataNode sends periodic heartbeat messages (every few seconds) to the NameNode.
- If a DataNode dies, the heartbeats will stop, and the NameNode will detect that the DataNode has died. The NameNode will then mark the DataNode as dead and will no longer forward any read/write request to that DataNode.
- Because of replication, the blocks stored on that DataNode have additional replicas on other DataNodes.
- The NameNode performs regular status checks on the file system to discover under-replicated blocks and performs a cluster rebalance process to replicate blocks that have less than the desired number of replicas.
What happens when the NameNode fails?
FsImage and EditLog
- NameNode is a single point of failure (SPOF). Will bring the entire file system down.
- Internally, the NameNode maintains two on-disk data structures that store the file system’s state: an FsImage file and an EditLog. FsImage is a checkpoint (or the image) of the file system metadata at some point in time, while the EditLog is a log of all of the file system metadata transactions since the image file was last created.
- All incoming changes to the file system metadata are written to the EditLog.
- At periodic intervals, the EditLog and FsImage files are merged to create a new image file snapshot, and the edit log is cleared out.
Metadata backup
- On a NameNode failure, the metadata would be unavailable, and a disk failure on the NameNode would be catastrophic because the file metadata would be permanently lost since there would be no way of knowing how to reconstruct the files from the blocks on the DataNodes.
- Thus, it is crucial to make the NameNode resilient to failure, and HDFS provides two mechanisms for this:
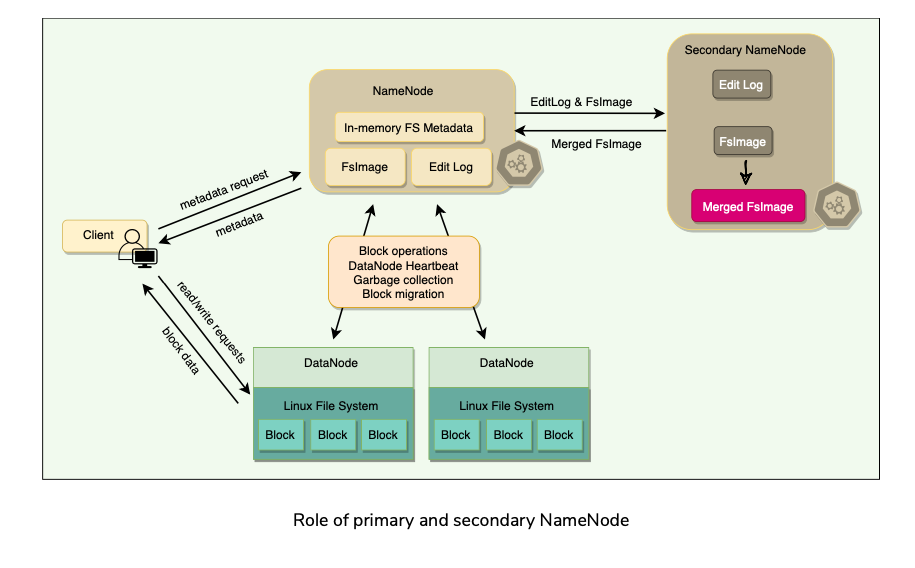
HDFS High Availability
Agenda
- HDFS high availability architecture
- Failover and fencing
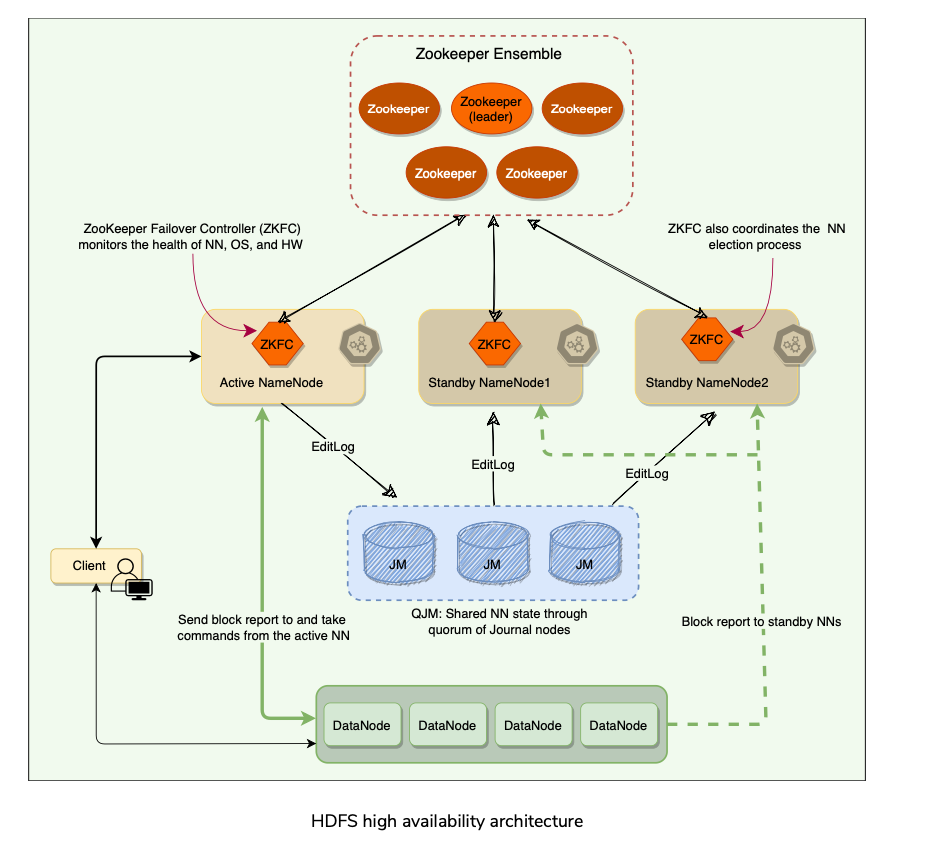
HDFS high availability architecture
Problem
- Although NameNode’s metadata is copied to multiple file systems to protect against data loss, it still does not provide high availability of the filesystem.
- If the NameNode fails, no clients will be able to read, write, or list files, because the NameNode is the sole repository of the metadata and the file-to-block mapping.
- In such an event, the whole Hadoop system would effectively be out of service until a new NameNode is brought online.
- To recover from a failed NameNode scenario, an administrator will start a new primary NameNode with one of the filesystem metadata replicas and configure DataNodes and clients to use this new NameNode.
- The new NameNode is not able to serve requests until it has
- On large clusters with many files and blocks, it can take half an hour or more to perform a cold start of a NameNode.
- Furthermore, this long recovery time is a problem for routine maintenance.
Solution
- Hadoop 2.0 added support for High Availability(HA).
- There are two (or more) NameNodes in an active-standby configuration.
- The active NameNode is responsible for all client operations in the cluster,
- Standby is simply acting as a follower of the active, maintaining enough state to provide a fast failover when required.
- For the Standby nodes to keep their state synchronized with the active node, HDFS made a few architectural changes:
Quorum Journal Manager(QJM)
- Provide a highly available EditLog.
- QJM runs as a group(usually 3 where 1 can fail) of journal nodes, and each edit must be written to a quorum (or majority) of the journal nodes.
- Similar to the way Zookeeper works except QJM doesn’t use ZooKeeper.
- HDFS High Availability does use ZooKeeper for electing the active NameNode (Master Election).
- The QJM process runs on all NameNodes and communicates all EditLog changes to journal nodes using RPC.
- Since the Standby NameNodes have the latest state of the metadata available in memory (both the latest EditLog and an up-to-date block mapping), any standby can take over very quickly (in a few seconds) if the active NameNode fails.
- However, the actual failover time will be longer in practice (around a minute) because the system needs to be conservative in deciding that the active NameNode has failed(Failure Detection).
- In the unlikely event of the Standbys being down when the active fails, the administrator can still do a cold start of a Standby. This is no worse than the non-HA case.
Zookeeper
- The ZKFailoverController (ZKFC) is a ZooKeeper client that runs on each NameNode and is responsible for coordinating with the Zookeeper and also monitoring and managing the state of the NameNode.
Failover and fencing
- A Failover Controller manages the transition from the active NameNode to the Standby. The default implementation of the failover controller uses ZooKeeper to ensure that only one NameNode is active(Single Leader). Failover Controller runs as a lightweight process on each NameNode and monitors the NameNode for failures (Failure Detection using Heartbeat), and triggers a failover when the active NameNode fails(New Leader Election).
- Graceful failover: For routine maintenance, an administrator can manually initiate a failover. This is known as a graceful failover, since the failover controller arranges an orderly transition from the active NameNode to the Standby.
- Ungraceful failover: In the case of an ungraceful failover, however, it is impossible to be sure that the failed NameNode has stopped running. For example, a slow network or a network partition can trigger a failover transition, even though the previously active NameNode is still running and thinks it is still the active NameNode.
- The HA implementation uses the mechanism of Fencing to prevent this “split-brain” scenario and ensure that the previously active NameNode is prevented from doing any damage and causing corruption.
Fencing
- Fencing is the idea of putting a fence around a previously active NameNode(Old Leader) so that it cannot access cluster resources and hence stop serving any read/write request. Two Fencing techniques:
HDFS Characteristics
Explore some important aspects of HDFS architecture.
Agenda
- Security and permission
- HDFS federation
- Erasure coding
- HDFS in practice
Security and permission
- Permission Model for files and director similar to POSIX.
- Each file and directory is associated with an owner and a group and has separate permission for Owner, vs Group members, vs Others, similar to POSIX.
- Similar 3 types of permissions R/W/X like POSIX:
- Optional support for POSIX ACLs to augment file permissions with finer-grained rules for named specific users or groups.
HDFS federation(NameNode Partitioning)
- Namenode keeps whole metadata in memory. Memory becomes a performance bottleneck for extremely large clusters and to server all metadata requests from a single node.
- To solve this problem, HDFS Federation was Introduced in HDFS 2.x.
- Allows a cluster to scale by adding NameNodes, each of which manages a portion of the filesystem namespace. /user & /root managed by NN1 and NN2.
- Under federation:
- Multiple NN can generate the same 64-bit BlockID for their blocks.
- To avoid this problem, a namespace uses one or more Block Pools, where a unique ID identifies each block pool in a cluster.
- A block pool belongs to a single namespace and does not cross the namespace boundary.
- The extended block ID, which is a tuple of (Block Pool ID, Block ID), is used for block identification in HDFS Federation.
Erasure coding
- By default, HDFS stores three copies of each block, resulting in a 200% overhead (to store two extra copies) in storage space and other resources (e.g., network bandwidth).
- Erasure Coding (EC) provides the same level of fault tolerance with much less storage space. In a typical EC setup, the storage overhead is no more than 50%.
- This fundamentally doubles the storage space capacity by bringing down the replication factor from 3x to 1.5x.
- Under EC, data is broken down into fragments, expanded, encoded with redundant data pieces, and stored across different DataNodes.
- If, at some point, data is lost on a DataNode due to corruption, etc., then it can be reconstructed using the other fragments stored on other DataNodes.
- Although EC is more CPU intensive, it greatly reduces the storage needed for reliably storing a large data set.
- References:
HDFS in practice
- Was primarily designed to support Hadoop MapReduce jobs by providing Distributed File System for Map and Reduce Operations.
- HDFS is now used with Many Big-Data Tools, e.g. in Several Apache Projects built on top of Hadoop, incl, Pig, Hive, HBase, Giraph etc.. Also GraphLab.
- Advantages of HDFS?
- Disadvantages of HDFS?
Summary
- Scalable distributed file system for large distributed data intensive applications.
- Uses commodity hardware to reduce infrastructure costs.
- POSIX-like(but not compatible) APIs for file operations.
- Random writes are not possible. Append-Only.
- Doesn’t support multiple concurrent writers to append to the same chunk like GFS.
- Single NameNode and Multiple DataNodes in initial architecture.
- Files are broken into 128 MB Blocks identified by 64-bit Globally unique block ID.
- Blocks are replicated to multiple machines(default 3,Configurable) to provide redundancy. 200% overhead on replication. Can be reduced to 50% by using Erasure Coding.
- DataNodes stores blocks on local disks as Linux Files.
- NameNode is coordinator for HDFS Cluster. Keeps track of all filesystem metadata.
- NameNode keeps all metadata in memory(for faster access). For Fault Tolerance(Node Crash), in-memory metadata changes are written to a Write Ahead Log(EditLog). For Disk Crash Tolerance, Edit Log can be replicated to a Remote File System(NFS) or QJM(Quorum Journal Manager) V2, or secondary NameNode(V1).
- NameNode doesn’t keep records of block replica locations on DataNodes. NameNode Heartbeats and Collects states from DataNodes and asks on which block replicas it holds at NameNode Startup or when DataNode joins the cluster.
- FsImage: NameNode checkpoints the EditLog into FsImage and serialized to disk and replicated to other nodes, so in case of fail-over or NameNode start, it can quickly use the Checkpoint and subsequent EditLog to build the state again.
- User applications Interact with HDFS using HDFS client, which interacts with NameNode for metadata, and directly talks to DataNode for read/write operations.
- DataNode and Clients use Checksums to validate data integrity of Blocks. Informs the NameNode to repair the replica if corrupted.
- Lazy Collection: Deleted file is renamed to hiddle name to be GC’ed later.
- HDFS is a strongly Consistent FS. Write is declared successful only if it is replicated to all the replicas.
- Cache: For Frequently accessed files, user specified file paths/blocks to the NameNode server, can be explicitly cached in DataNode’s memory in an Off-heap block cache.(GFS just uses Linux’s Buffer Cache).
System Design Patterns
- Write Ahead Log - Fault Tolerance/Reliability.
- HeartBeat
- Split Brain
- CheckSum - Data Integrity.
Reference
- HDFS Paper
- HDFS High Availability
- HDFS Architecture
- Distributed File Systems:A Survey
Paper Link: https://pages.cs.wisc.edu/~akella/CS838/F15/838-CloudPapers/hdfs.pdf
Last updated: March 15, 2026
Questions or discussion? Email me