Paper: Megastore
Megastore
Google 2011
No SQL Database with strong consistency*(Within 1 partition).
Replicas spread across data centers for fault tolerance.
Built on top of BigTable(+ GFS), Paxos(Distributed Consensus) is used for strong consistency.

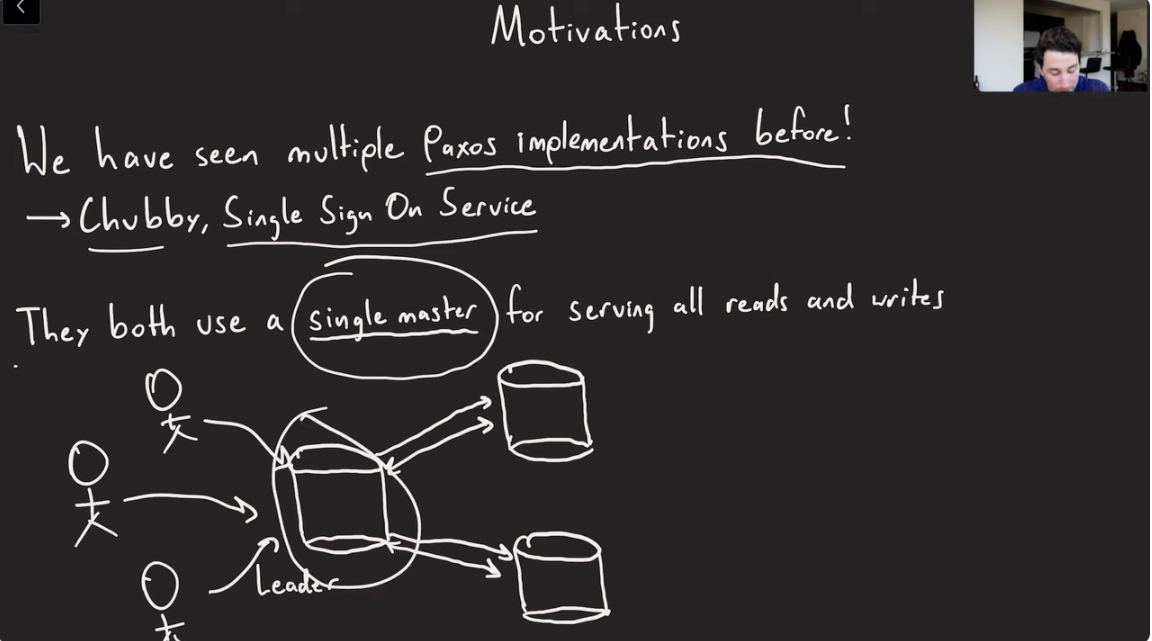
We have seen multiple Paxos implementations before, Chubby, Single Sign On(SSO).
Motivations behind building Megastore
Single Leader Paxos
Pros
- PiggyBacking:Prepare phase of write n+1 can be piggybacked on the commit of write n.
- Local reads can be served from the master.
Cons
- Follower replicas are just wasting resources.
- Master failover takes a while and we need to wait for master lease timeout.
- Servers that are not close to the master but are close to the end user still have to go through the masters.

Megastore proposed Improvements
- Writes can be proposed by ANY replica.
- Reads can be initiated by any replica
- No more need to handle Master Failover.

Entity Groups(Partitions)
- Paxos maintains a distributed log across computers. We use it to create a database write ahead log.
- If we use one log for the entire database, every write would compete to be the next spot in the log.
- Partition the log by Entity Group.

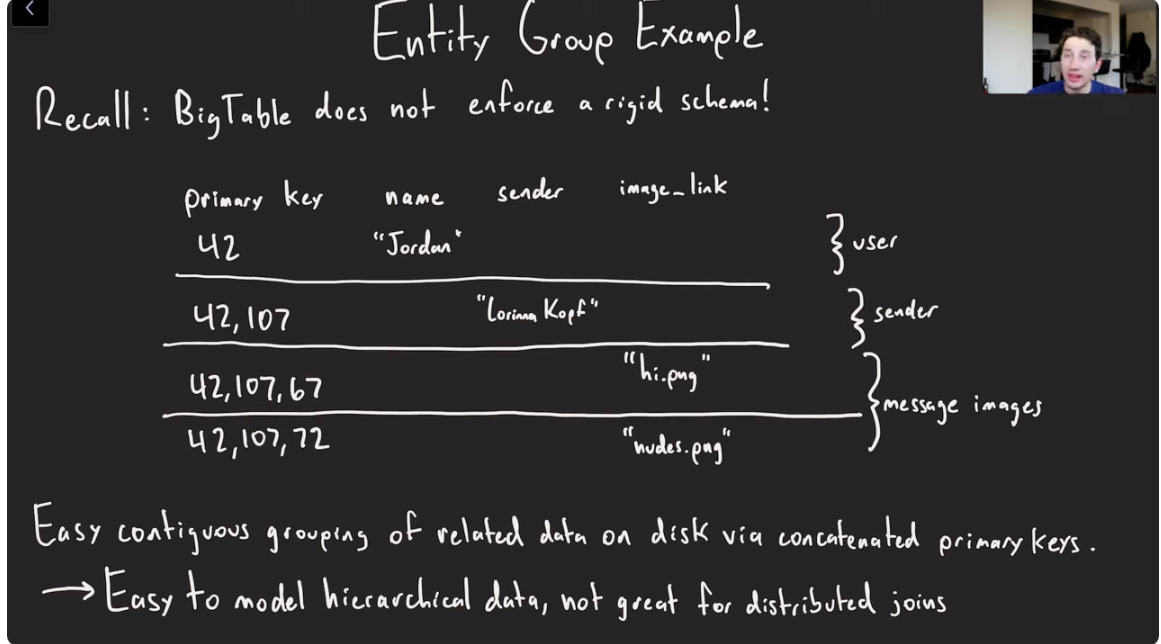
Entity Group Example
Megastore allows you to do a ton of data denormalization because BigTable provides a flexible schema.
- Helps keep the related data co-located(contiguous) on 1 single computer , so that you don’t need to perform any distributed Joins(across partitions) or 2PC.
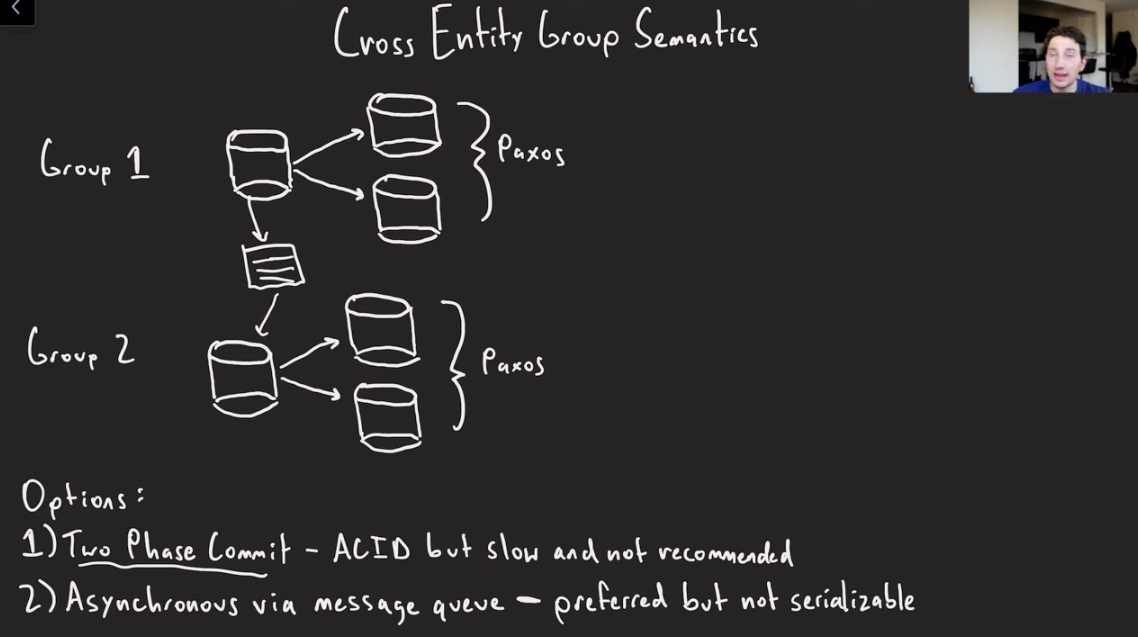
Cross Entity Group Semantics
Megastore allows doing Cross Entity Group(Partitions) writes.
- Two Phase commit: Provides ACID guarantees but slow and not recommended.
- Asynchronous via Message Queue: Preferred but not serializable.
Replication Overview
- Recall: Prepare phase is used to determine which replica gets to write the current log entry.
- Writes:

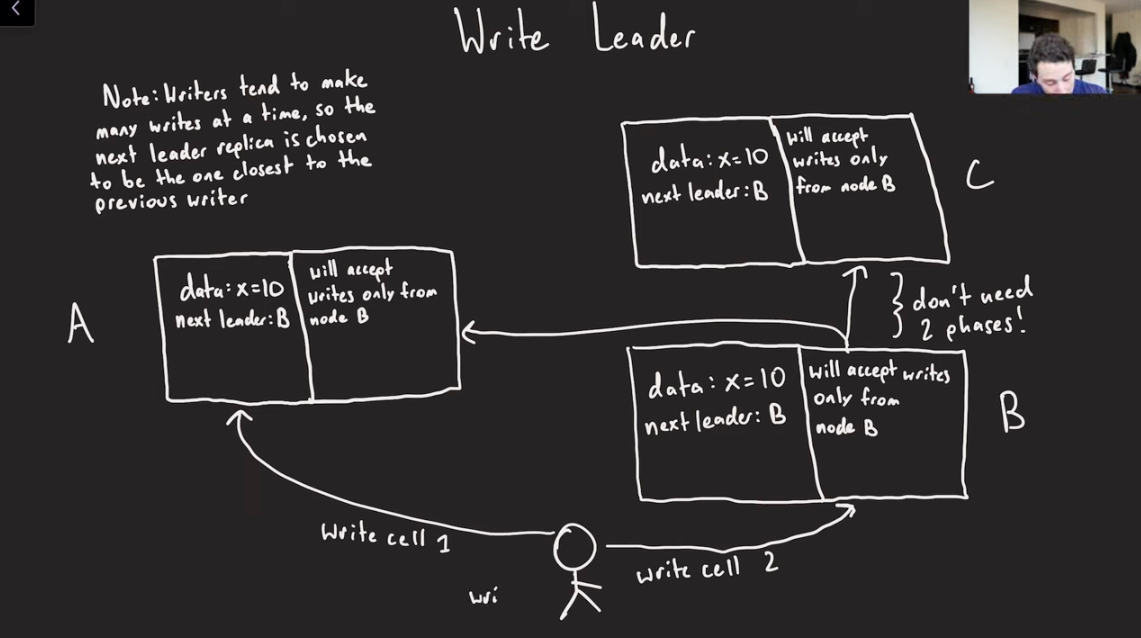
Write Leader
- Since the leader replica of the next log cell is already determined during the previous commit requests, when the actual next write comes for the log cell n+1 to leader replica B, it is already known to replica A and C to only accept writes from B for that Log Cell.
- This way, we don;t need to do a 2PC for establishing which is the next log item to write via distributed consensus.
- Writers tend to make many writes at a time, so the next leader replica is chosen to be the one closest to the previous writer.
- What if the Leader Replica goes down before the write for that phase goes through?
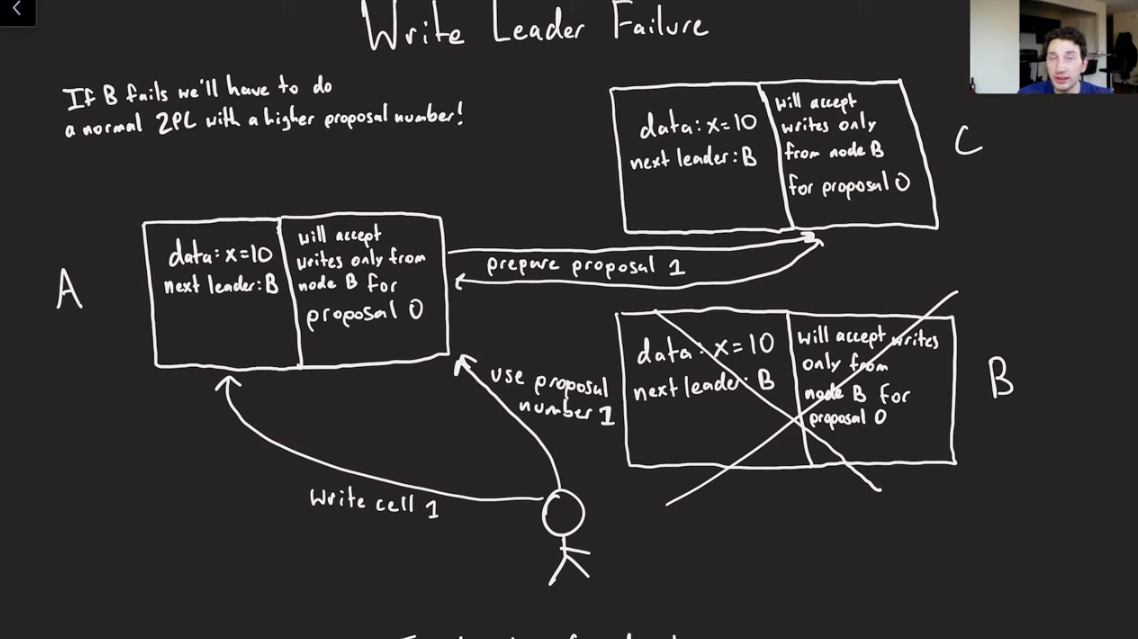
Write Leader Failure
- What if B goes down before it actually makes a commit?
- We use the concept of a Proposal number(Generation Number/Epoch Number).
- Node A/C would instantaneously accept write if they would see write from Node B for Proposal 0.
- However, if Node B goes down, Proposal 0 would never come.
- Coordinator(down below in picture), sees that Node B is down(Failure detection), and decides to ask A, let’s start Proposal 1 for this log cell.
- A can then reach out to C with Proposal 1.
- C sees that this proposal 1 is higher than proposal 0, so it can accept this thing.
- Now A needs to do a fresh 2PC to C.
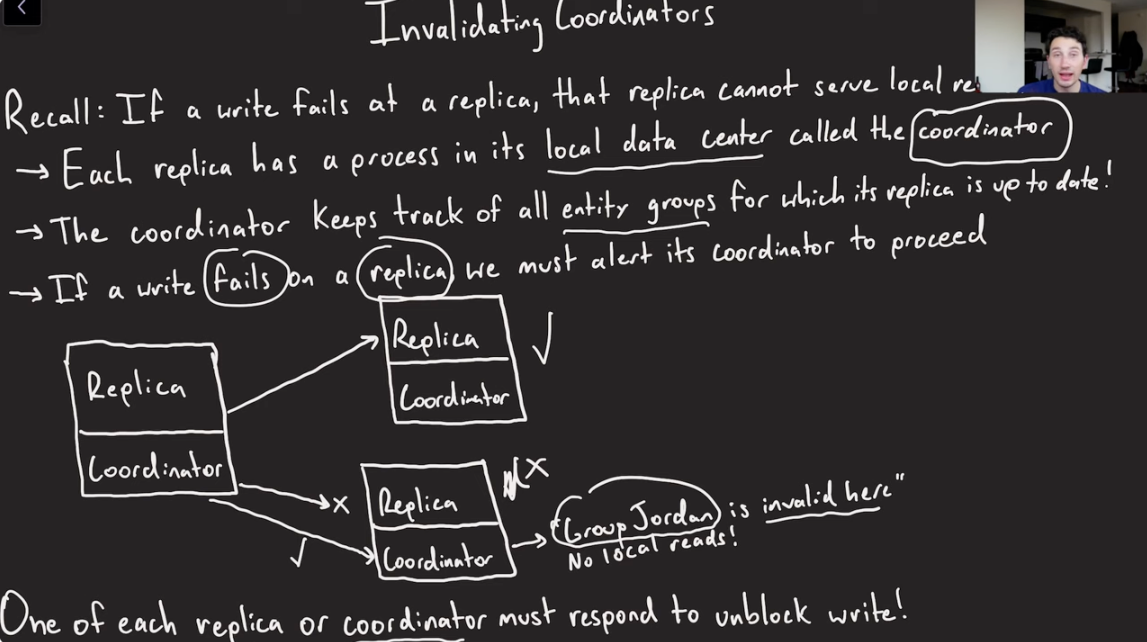
Invalidating Coordinators
- If a write at a replica doesn’t go through, that replica cannot serve the local reads.
- Every replica has a process in its local datacenter, called the coordinator.
- Coordinator keeps track of all entity groups for which this replica is up to date.
- If a write fails on a replica, we must alert its coordinator to proceed.
- One of each replica or coordinator must respond to unblock write.
Coordinator Failure
- What happens if a Coordinator and its replica goes down(Data Center Failure)?
- Solution:
- Coordinator grabs chubby locks in multiple other data centers.
- If the coordinator loses connection(locks) to the majority of data centers, then it knows it is probably partitioned from the rest of the replicas.
- Writes can then proceed w/o the replica since the other failed coordinator/replica are aware that they can’t serve local reads.
- Not perfect. Edge case.

Reading Data
- The responsibility of the coordinator is to answer, can my local replica be read from for that particular entity group, or do you have to read from another replica or do a quorum read?
- If the coordinator says, Replica is up to date, read locally from there. Otherwise
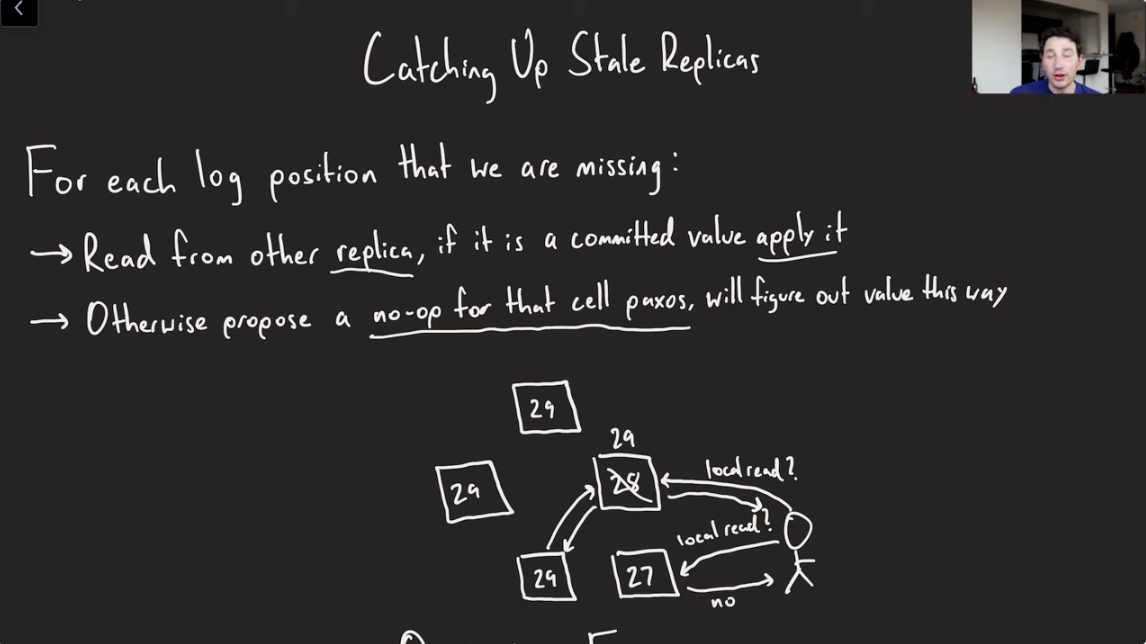
- Figure out the last known log entry by doing quorum read.
- Pick a replica(either most up to date, or most responsive).
- If the selected replica is behind, we are going to read from another replica to catch up its log, and then tell its coordinator that it is valid now(after catch up).
- Perform local reads on that replica.

Catching up Stale Replica
Production Experience


Paper Link: http://www.cidrdb.org/cidr2011/Papers/CIDR11_Paper32.pdf
Last updated: March 15, 2026
Questions or discussion? Email me