Paper: Spanner
Spanner: Google’s Globally-Distributed Database
Abstract
- Spanner is Google’s scalable, multi-version, globally-distributed, and synchronously-replicated database which supports externally-consistent(Linearizable) distributed transactions.
- Paper describes how Spanner is Structured, feature set, rationale behind various design decisions, and a Novel Time API that exposes clock certainty.
Introduction
- Spanner shards data across many sets of Paxos state machines in DCs spread across the world.
- Replication for global availability and geographic locality, clients automatically failover between replicas.
- Automatically reshards data across machines as the amount of data or the number of servers changes, and it automatically migrates data across machines (even across datacenters) to balance load and in response to failures.
- Designed to scale up to millions of machines across hundreds of data centers and trillions of database rows.
- Applications can use Spanner for high availability, even in the face of wide-area natural disasters, by replicating their data within or even across continents.
- BigTable problems
- Megastore supports semi-relational data model and synchronous replication, despite its relatively poor write throughput.
- Spanner has evolved from a Bigtable-like versioned key-value store into a temporal multi-version database.
- Globally distributed features:
- TrueTime API and its implementation(Key enabler of the above properties)
Spanner Implementation
Directory abstraction(unit of data movement) to manage replication and locality.
Data model. Spanner looks like a relational database instead of a key-value store.
Applications can control data locality.
A Spanner deployment is called a universe.
Spanner is organized as a set of zones.
A zone has **one zonemaster(**assigns data to spanservers) and between one hundred and several thousand spanservers(serve data to clients).
Per-zone location proxies are used by clients to locate the spanservers assigned to serve their data.
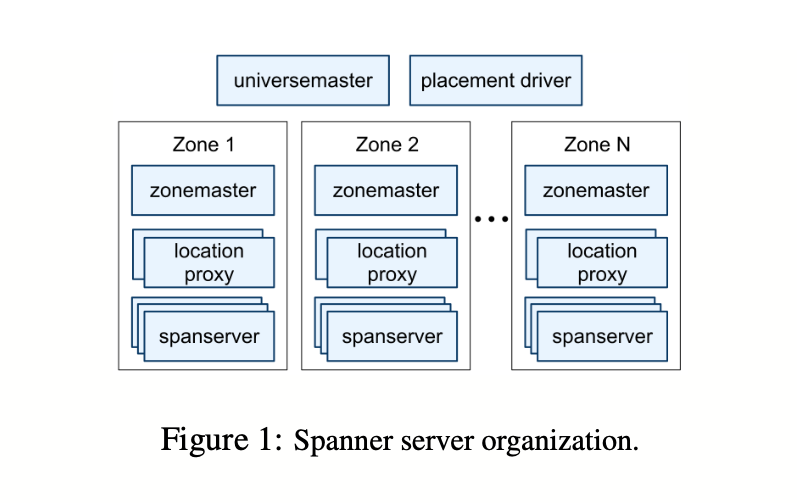
Universe master(Singleton) is primarily a console that displays status information about all the zones for interactive debugging
Placement driver(Singleton) handles automated movement of data across zones on the timescale of minutes.
SpanServer Software Stack
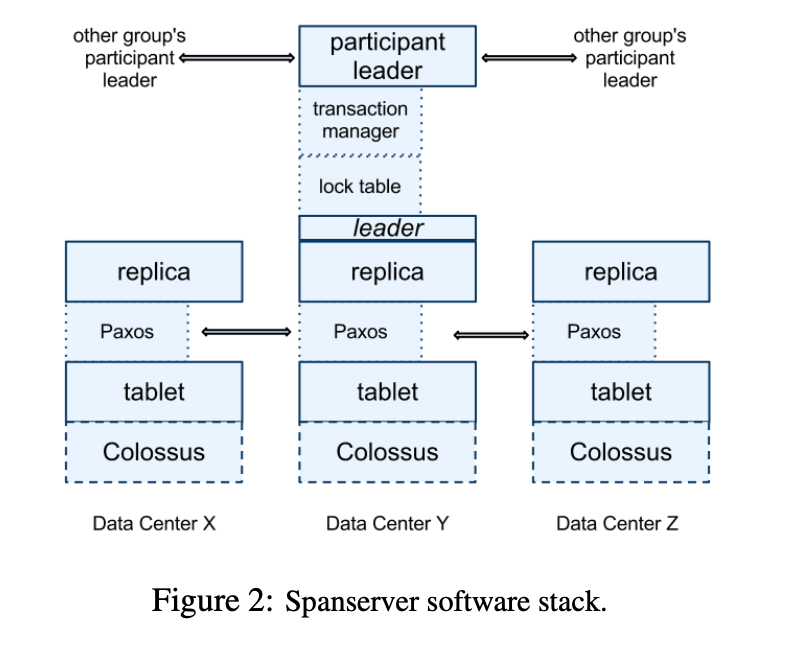
Spanserver implementation to illustrate how replication and distributed transactions have been layered onto our Bigtable-based implementation.
Each spanserver is responsible for between 100 and 1000 instances of a data structure called a tablet.
A tablet is similar to Bigtable’s tablet abstraction, in that it implements a bag of the following mappings
Unlike Bigtable, Spanner assigns timestamps to data which is why
A Spanner’s tablet’s state is stored in a set of B-tree-like files and a write-ahead log, all on a distributed file system called Colossus (the successor to the Google File System.
To support replication, each spanserver implements a single Paxos state machine on top of each tablet.
Each state machine stores its metadata and log in its corresponding tablet
Paxos implementation supports long-lived leaders with time-based leases(D: 10s).
Current Spanner implementation logs every Paxos write twice:tablet’s & Paxos log.
Implementation of Paxos is pipelined, so as to improve Spanner’s throughput in the presence of WAN latencies; but writes are applied by Paxos in order.
The Paxos state machines are used to implement a consistently replicated bag of mappings.
Writes must initiate the Paxos protocol at the leader;
Reads access state directly from the underlying tablet(sufficiently up-to-date).
Set of replicas is collectively a Paxos group.
At leader replica, each spanserver implements a lock table for concurrency control.
Bigtable and Spanner are designed for long-lived transactions(e.g. for report generation, which might take on the order of minutes) which perform poorly under optimistic concurrency control in the presence of conflicts.(What?)
Operations that require synchronization, such as transactional reads, acquire locks in the lock table; other operations bypass the lock table.
Each spanserver(at leader replica) implements a transaction manager to support distributed transactions.
If a transaction involves only one Paxos group (as is the case for most transactions), it can bypass the transaction manager, since the lock table and Paxos together provide transactionality.
If a transaction involves more than one Paxos group, those groups’ leaders coordinate to perform a two-phase commit.
The state of each transaction manager is stored in the underlying Paxos group (and therefore is replicated).
Directories and Placement
On top of the bag of key-value mappings, the Spanner implementation supports a bucketing abstraction(Directory), which is a set of contiguous keys that share a common prefix.
A directory is the unit of data placement.
The fact that a Paxos group may contain multiple directories implies that a Spanner tablet is different from a Bigtable tablet. Former is not necessarily a single lexicographically contiguous partition of the row space.
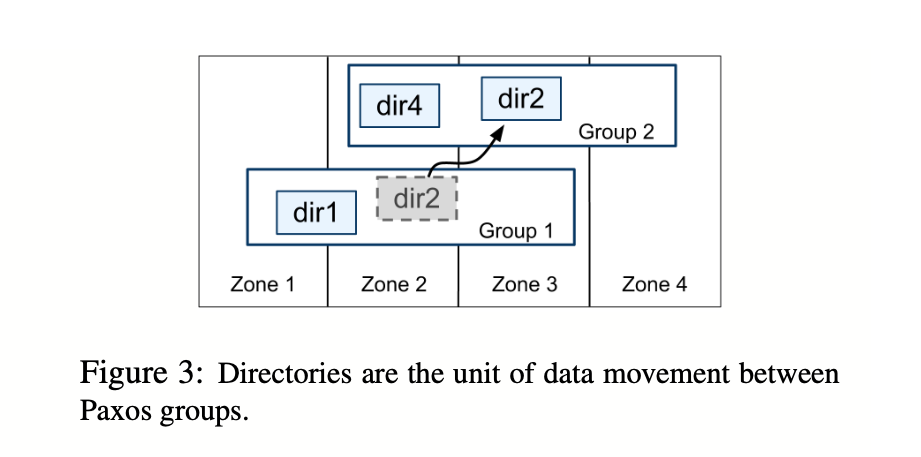
Movedir is the background task used to move directories between Paxos groups.
Application specifies a directory’s geographic-replication placement.
The design of placement-specification language separates responsibilities for managing replication configurations.
An application controls how data is replicated, by tagging each database and/or individual directories with a combination of those options.
Spanner will Shard/Partition a directory into multiple fragments if it grows too large.
Data Model
Spanner offers a
DataModel Use Case:

This interleaving of tables to form directories is significant because it allows clients to describe the locality relationships that exist between multiple tables, which is necessary for good performance in a sharded, distributed database. Without it, Spanner would not know the most important locality relationships.
TrueTime
TrueTime explicitly represents time as a TTinterval, which is an interval with bounded time uncertainty(unlike standard time interfaces that give clients no notion of uncertainty).

The endpoints of a TTinterval are of type TTstamp.
The time epoch is analogous to UNIX time with leap-second smearing.
The underlying time references used by TrueTime are GPS and atomic clocks because they have different failure modes.
TrueTime is implemented by a set of time master machines per datacenter and a timeslave daemon per machine.
All masters’ time references are regularly compared against each other.
Every daemon polls a variety of masters to reduce vulnerability to errors from any one master.
Uncertainty Range 1-7 ms with 4 ms most of the time at a Daemon poll interval of 30 sec and current drift applied rate is 200 microseconds/second.
Concurrency Control
- TrueTime API is used to guarantee correctness properties around concurrency control, and how those properties are used to implement features such as externally consistent transactions, lock-free read-only transactions, and non-blocking reads in the past.
- Important to distinguish writes as seen by Paxos Writes vs Spanner client writes.
Timestamp Management
- Spanner supports:

Paxos Leader Leases
- Spanner’s Paxos implementation uses timed leases to make leadership long-lived (10 seconds by default).
- Leader Election
Assigning Timestamps to RW Transactions
- Transactional reads and writes use two-phase locking(Reads & Writes block each other).
- As a result, they can be assigned timestamps at any time when all locks have been acquired, but before any locks have been released.
- For a given transaction, Spanner assigns it the timestamp that Paxos assigns to the Paxos write that represents the transaction commit.
- Spanner depends on the following monotonicity invariant: within each Paxos group, Spanner assigns timestamps to Paxos writes in monotonically increasing order, even across leaders.
- Spanner also enforces the following external-consistency invariant: if the start of a transaction T2 occurs after commit of a transaction T1, then the commit timestamp of T2 must be greater than the commit timestamp of T1.
Serving Reads at a Timestamp
Assigning Timestamps to RO Transactions
Details
Read Write Transactions
- Like Bigtable, writes that occur in a transaction are buffered at the client until commit.
- As a result, reads in a transaction do not see the effects of the transaction’s writes. This design works well in Spanner because a read returns the timestamps of any data read, and uncommitted writes have not yet been assigned timestamps.
- Reads within read-write transactions use wound-wait to avoid deadlocks.
Jordan: Google Spanner(2013)
Strongly consistent SQL Database via Paxos.
Supports causally consistent Non-Blocking read-only Snapshots over multiple nodes at a time even though they are distributed. This is not something you could do in your traditional database. Causal Consistency
Write B is causally dependent on Write A if
Can be achieved by using Lamport Clocks.
Spanner is both externally and causally consistent.
The order of writes to the database is the order in which the events actually happened.
Formally:
Spanner Details
- Spanner’s Design looks similar to Megastore to ensure strong consistency.
Paper Link: https://static.googleusercontent.com/media/research.google.com/en//archive/spanner-osdi2012.pdf
Last updated: March 15, 2026
Questions or discussion? Email me