Paper: High Performance IO For Large Scale Deep Learning
High Performance I/O For Large Scale Deep Learning
Ideas Explored(TLDR)
- WebDataset(Large Sharded Datasets instead of smaller Random Reads)
- AIStore(S3 compatible Object store w/ Caching) instead of Distributed File Systems like GFS/HDFS.
Background
- Deep learning training needs Petascale datasets.
- Existing Distributed File systems not suited for access patterns of DL jobs.
- DL Workloads: Repeated random access of training datasets(not High throughput sequential IO).
- DL datasets are transformed to shard collections from the original dataset to change access patterns from random reads to sequential IO.
- DL Model Training Steps
- Traditional Big Data ML Storage solutions
- Requirements for Large scale Deep Learning Storage Solutions
AI Store
Provide infinitely scalable namespace over arbitrary numbers of Disks(SSDs & HDDs).
Conventional Metadata servers related bottlenecks eliminated by having data flowing directly b/w Compute Clients and clustered storage Targets.
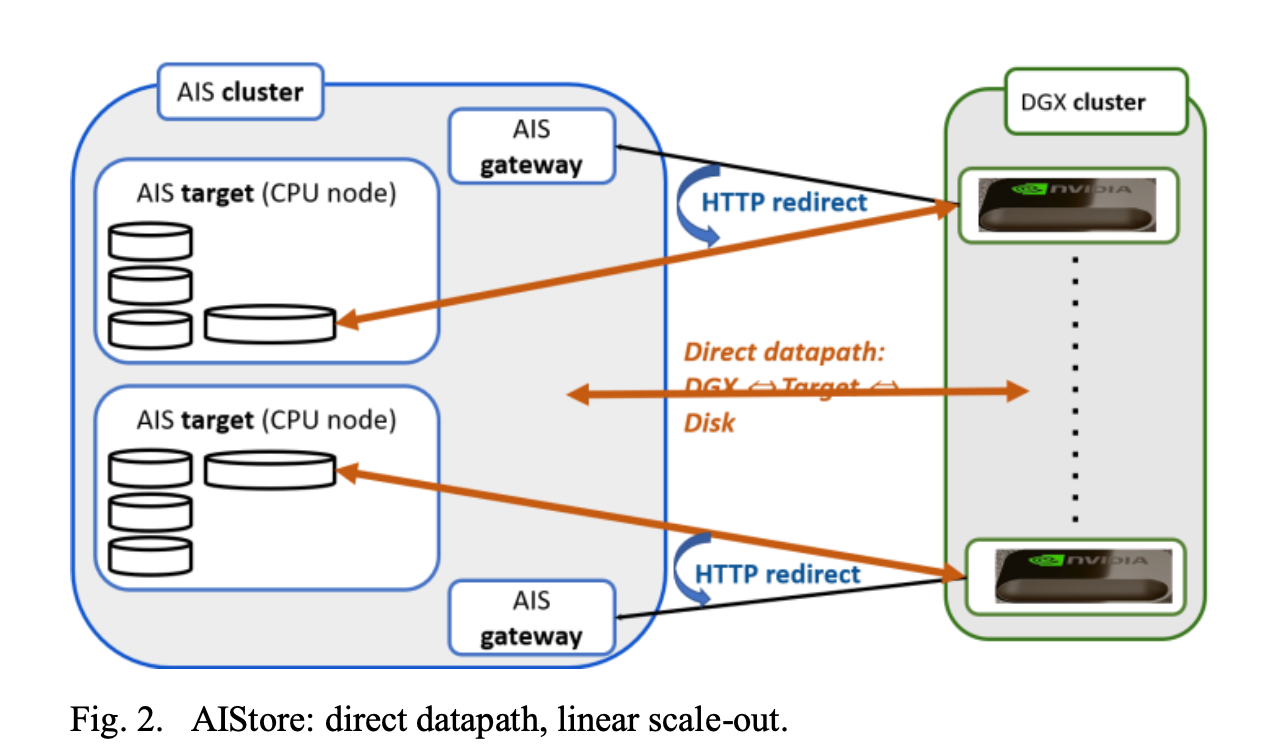
Lightweight, scale-out object store w/ S3 semantics. Also Integrates natively w/ S3 storages.
High performance via HTTP Redirects, client receives objects via direct connection to the storage server holding the object.
Serve as Large scale caching tier(Performance tier b/w Cold data & DL jobs) w/ Scale-out & no Limitations.
Open Source, written in GO, runs on commodity hardware(K8s, Linux nodes or clusters).
Other features
WebDataSet
- Defined Storage convention for existing File-based Datasets on existing Formats for adoption of Sharded Sequential Storage.
- Storage Format: WebDataset datasets are represented as standard POSIX tar files in which all the files that comprise a training sample are stored adjacent to each other in the tar archive.
- Library : WebDataSet Library is a drop-in replacement for Python DataSet API to access Record-Sequential(Sharded Key-Value) storage w/ minimal client changes.
- Server: Can read from any Input stream LocalFiles, Web Servers, Cloud Storage servers.
Small File Problem
- Large Scale DL Datasets have Billions of small files.
- Solution 1: Archival tools transform a small-file dataset into a dataset of larger shards.
- Solution 2: Scalable storage access
- AIStore gateways (aka AIS proxies)
Shards and Records
- DL Datasets = Billions/Trillions of small samples leading to small file problems.
- 4KB random read throughput = SSD = 200 MB/s - 900 MB/s = HDD Sequential read performance.
- Performance at scale for DL workloads require optimized read access patterns and not 4KB random reads.
- AIS supports automated user-defined pre-sharding and offloading to storage clusters.
- Best Toolchain, IO Friendly Sharding Format?
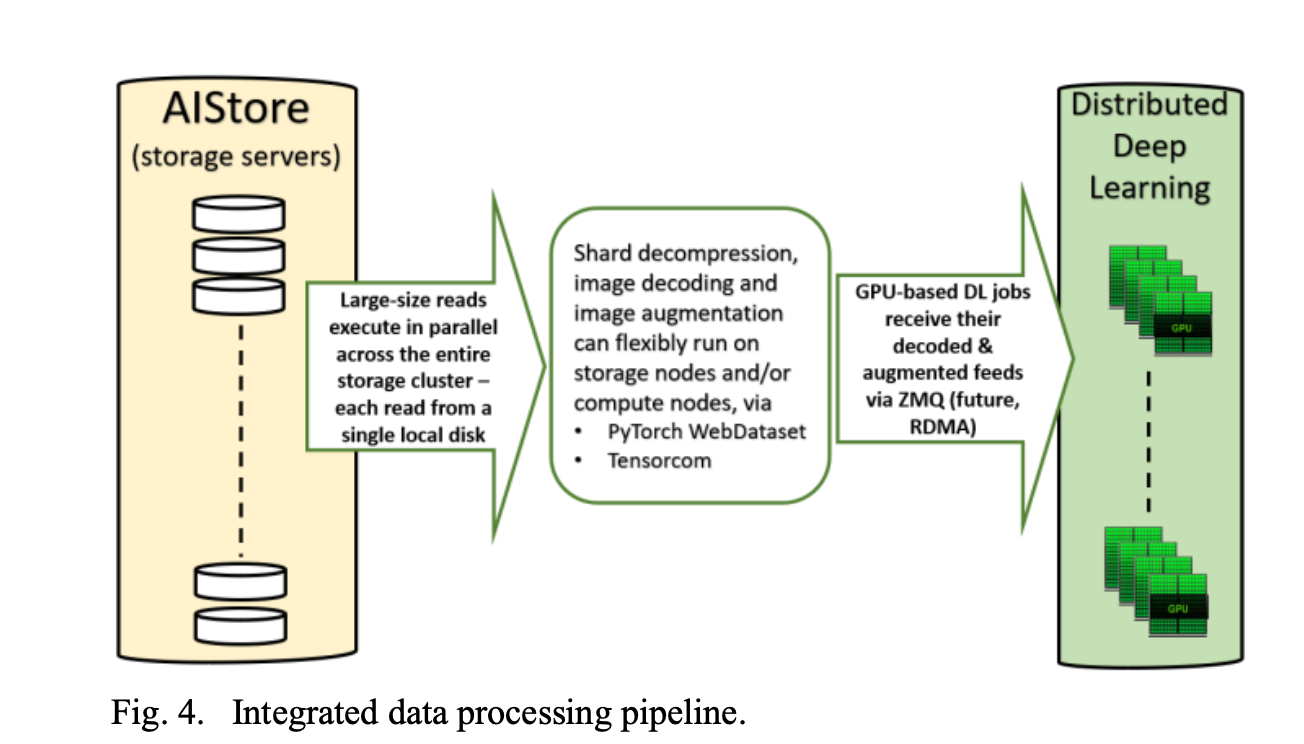
Core Ideas To support new DL Pipelines
- Large Sharded Reads.
- Highly scalable storage access protocol
- Independently scalable pipeline stages, I/O, Decoding, Augmentation, Deep Learning.
- Easy to assign any component(Compute or Storage) to K8s Node.
Benchmarking
- Lack of established/standardized deep learning benchmarks at the time that run DDL(Distributed Deep Learning) while Isolating Storage IO contribution to DDL performance.
- Didn’t want to go w/ Artificial “DDL-Like” synthetic workloads.
- Decided to benchmark end-to-end w/ Training and Inference particular DL framework w/ a fixed DL model.
- Metric of interest: how quickly the training/evaluation loop iterates and consumes data from the DataLoader pipeline.
- Hardware
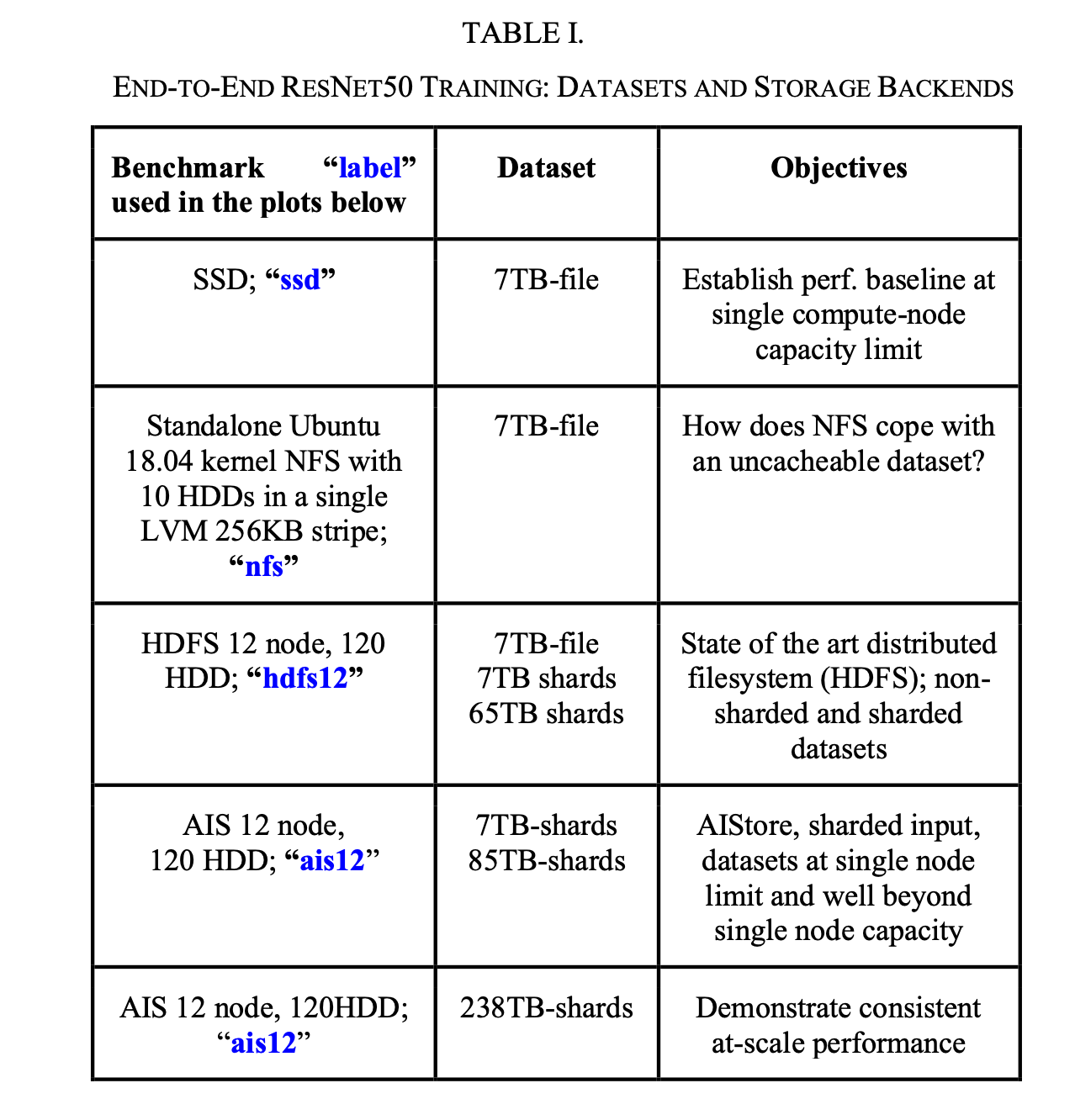
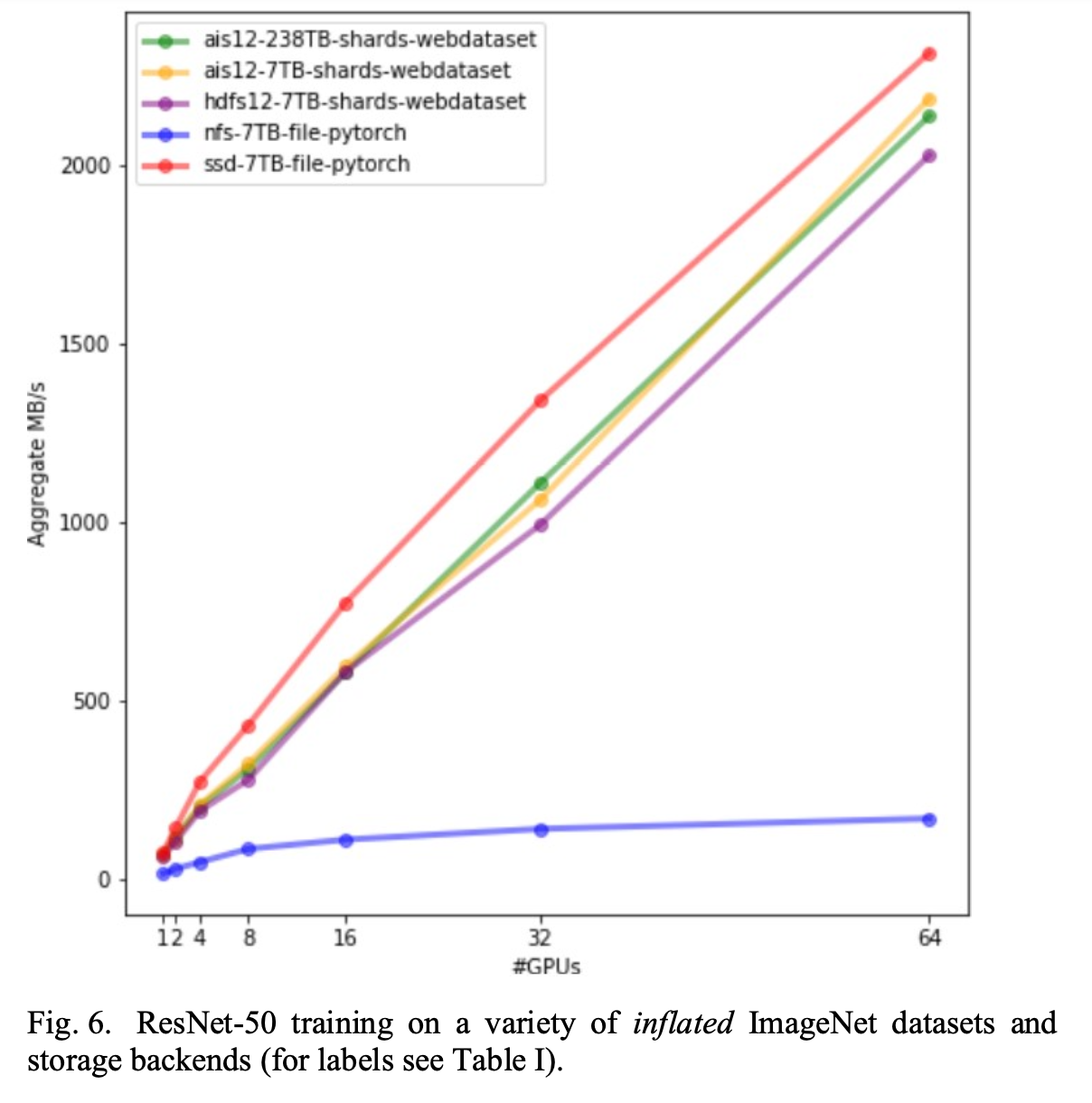
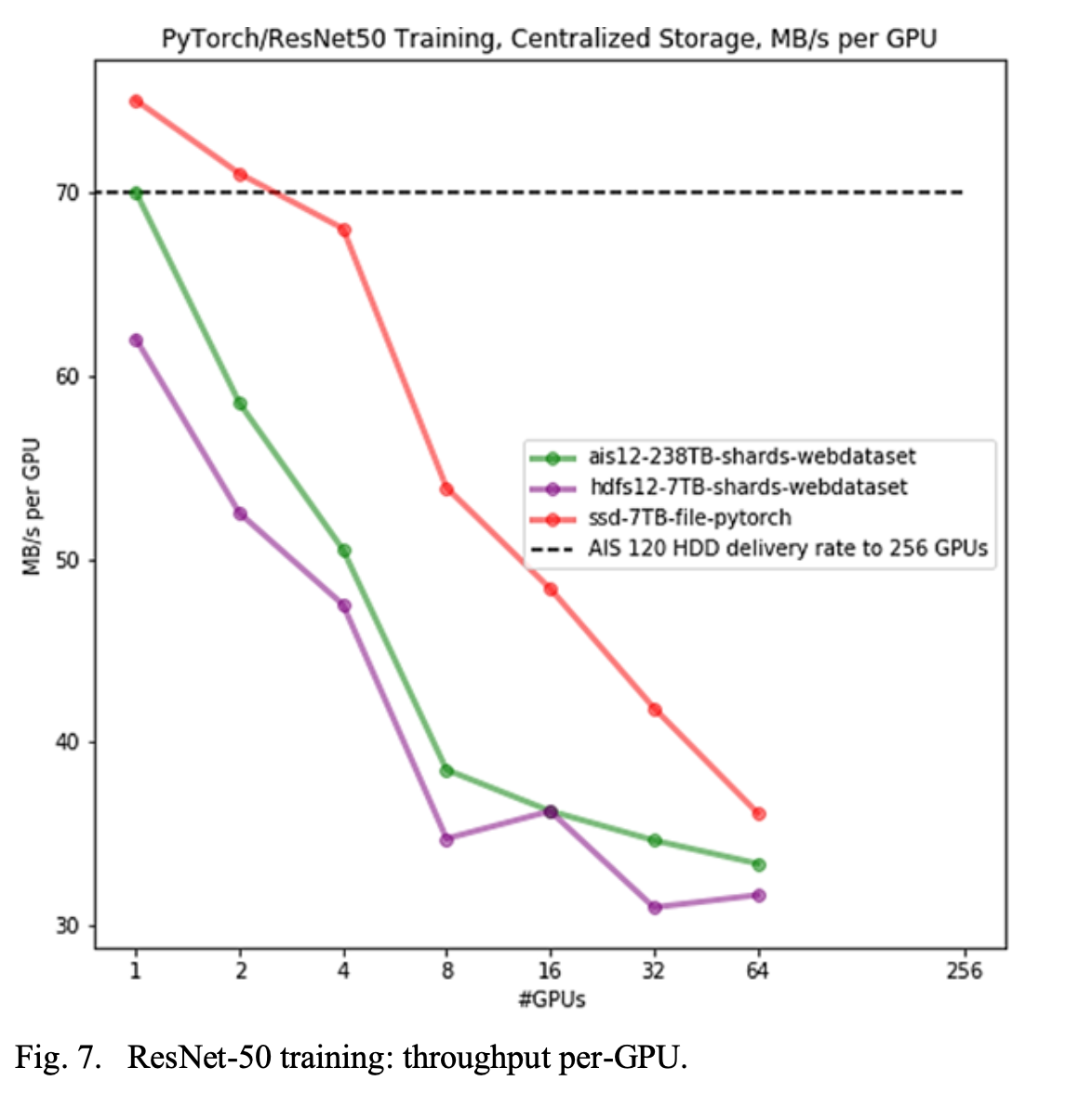
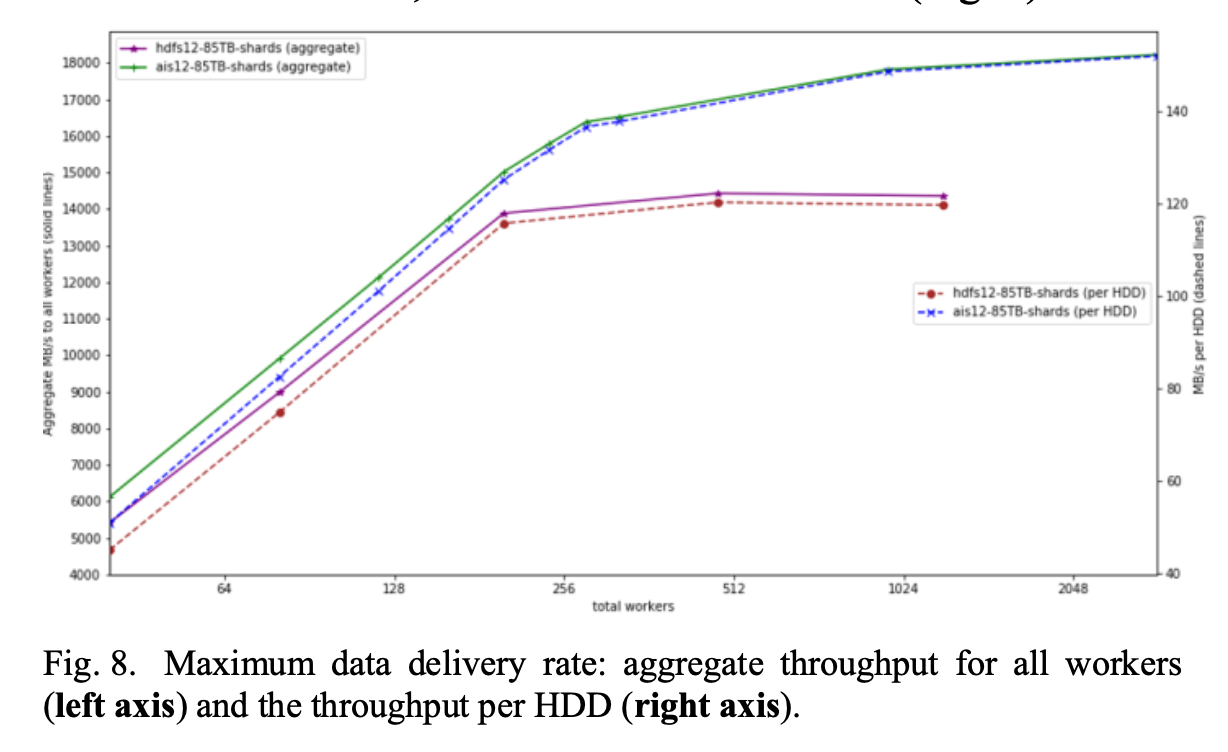
Result:
- Storage Format Change(WebDataSet) even on HDD gets the performance as close to Non-Sharded(DataSet) w/ SSD.
- AI Store’s performance w/ WebDataSet is better than Standard HDFS based WebDataset.
- AI Store scales better compared to HDFS especially for Large number of Small files use cases as well as supporting a large number of Clients(GPU Nodes) as it avoids centralized NameNode like In HDFS.
- AIStore delivers 18GB/s aggregated throughput, or 150MB/s per each of the 120 hard drives – effectively, a hardware-imposed limit. HDFS, on the other hand, falls below AIS, with the gap widening as the number of DataLoader workers grows.
Paper Link: https://arxiv.org/pdf/2001.01858
Last updated: March 15, 2026
Questions or discussion? Email me